
Blog
Why containment is the real metric for Voice AI in customer service
Discover why containment, not deflection, is the key metric for Voice AI in customer service, enhancing resolution and satisfaction for both customers and agents.
For technology leaders like you, the challenge is no longer if AI can create value—it’s how to make it enterprise-ready, scalable, and future-proof. That’s where ML6 comes in. We combine technical excellence with scalable engineering to solve your toughest challenges and build your boldest ideas.




Stay in the loop with stories from our team, success cases from our clients, and news on what we’re building behind the scenes. Whether it's a deep dive into the latest in AI, a behind-the-scenes look at a real-world implementation, or product updates we’re proud of — here’s what’s been happening lately.
Discover why containment, not deflection, is the key metric for Voice AI in customer service, enhancing resolution and satisfaction for both customers and agents.
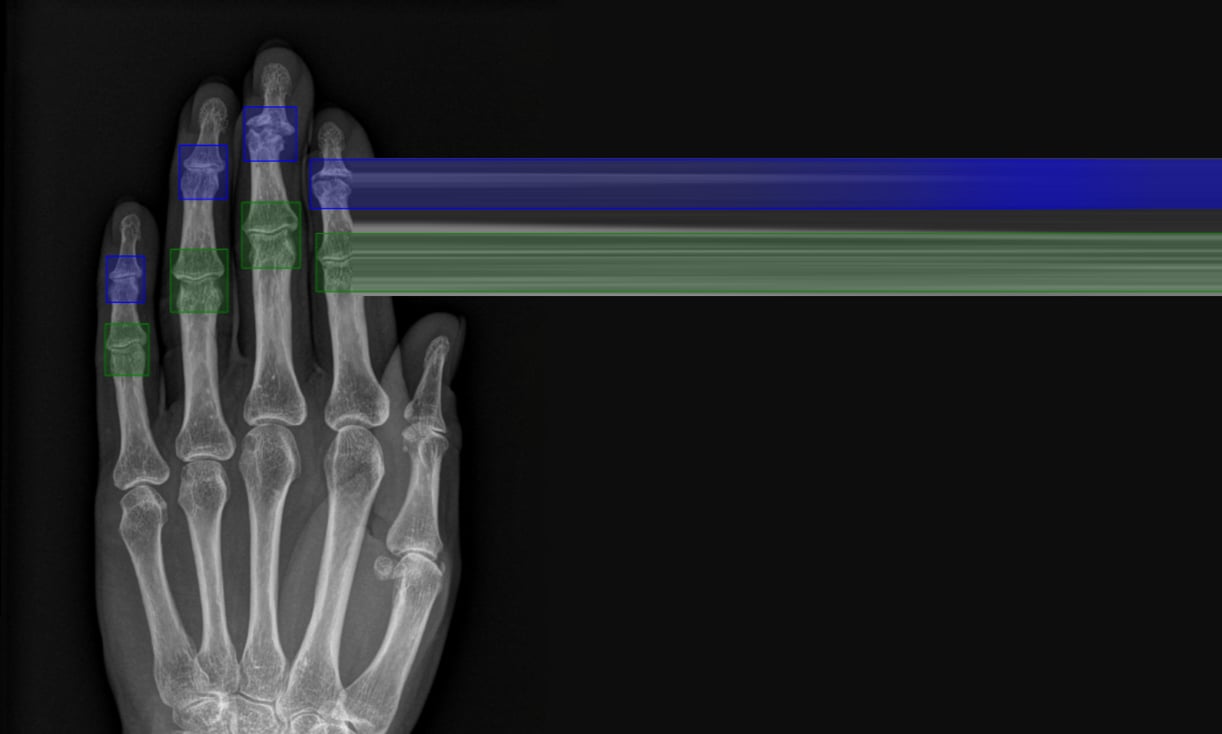
Explore how a team developed an AI pipeline to score erosive hand osteoarthritis from X-rays, achieving significant clinical improvements in just one week.

What is the environmental impact of generative AI? Explore energy use, carbon footprint, and why AI’s impact is so difficult to measure.
