

Executive summary
Self-hosting open-weight LLMs are often sold as a way to cut token costs, but that's rarely the real payoff—aggressive pricing from API providers and marketplaces means self-hosting only wins on price for specific, high-volume workloads. Its true value lies elsewhere: data control, sovereignty, auditability, customization, and resilience. Because of this, most companies shouldn't choose between "API everywhere" or "self-host everything," but instead build a routed portfolio—frontier APIs for hard or ambiguous tasks, marketplaces for price discovery and burst capacity, and self-hosted models where volume and sensitivity justify the operational investment. Once capacity is owned, the real challenge shifts from procurement to portfolio management, since fixed infrastructure only pays off when a steady mix of models and agents keeps it in use. The key question becomes not "what's cheapest?" but "what's the cheapest model, agent, and deployment pattern that meets our quality, latency, compliance, and utilization needs?"—a question ML6's AI engineering practice helps clients answer. That is the frontier this article maps, and the one ML6's AI engineering practice builds with clients.
The token explosion: why bills rise as models get cheaper
The macro trend behind every AI budget is genuinely counterintuitive: the price of a token has collapsed and total spend on tokens has exploded at the same time. Both are true, and the gap between them is where enterprise AI budgets quietly disappear.
It’s a real-life demonstration of Jevons paradox: token demand is highly elastic (price-elasticity roughly 1.2 to 1.8), so every 10% price cut drives 12-18% more tokens and the bill still rises. Cheaper tokens do not shrink spend; they enlarge the set of things worth spending tokens on.
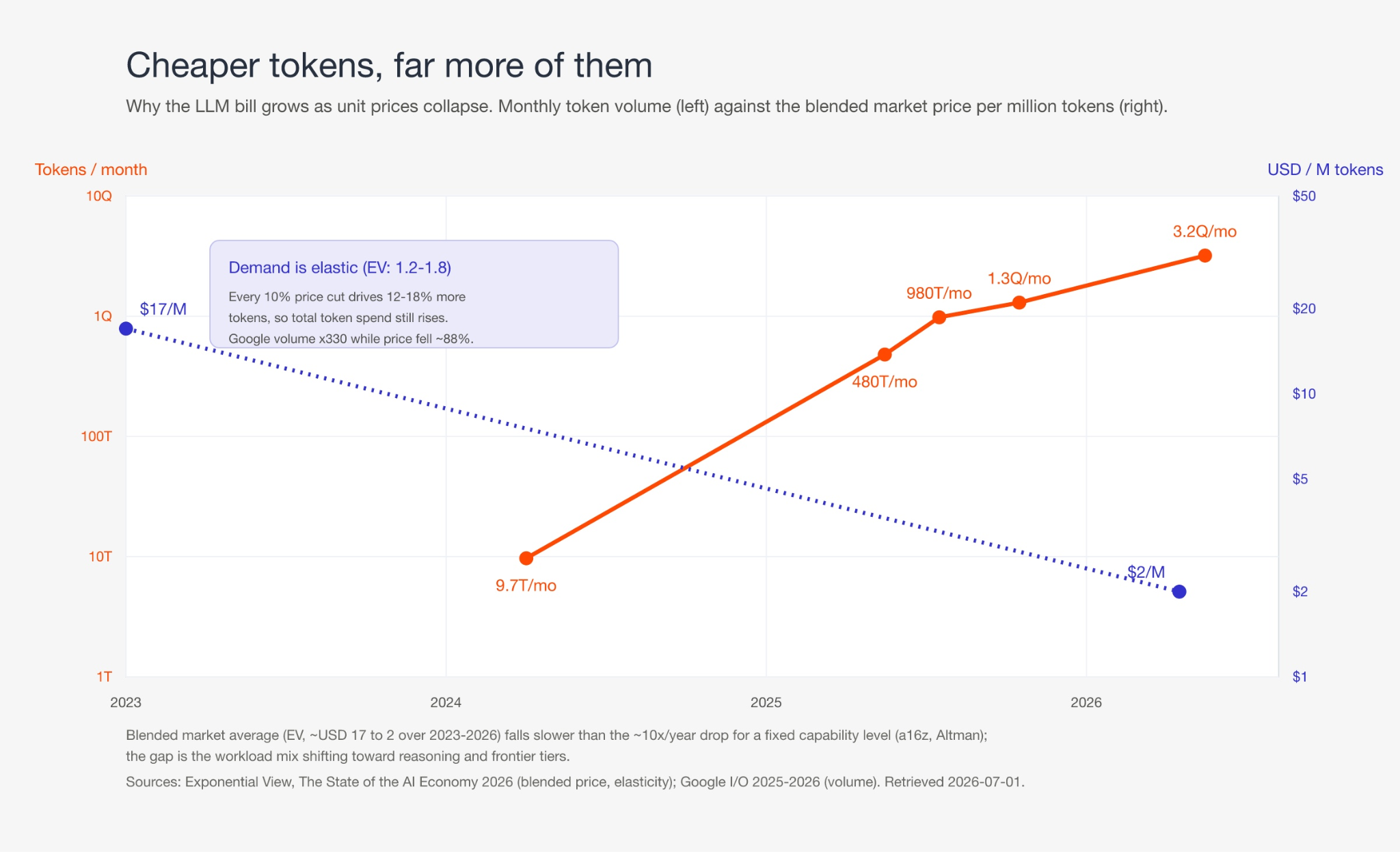
Three anchors to understand where we’re at in July 2026. Inference cost for a fixed capability level has fallen roughly 10x per year since 2021 (a16z's "LLMflation"), and Epoch AI measures a median ~50x annual price decline across benchmarks. Global inference volume passed an estimated ~30 quadrillion tokens per month by early 2026, growing ~14x year over year (Exponential View); Google alone went from ~9.7 trillion tokens a month in early 2024 to ~3.2 quadrillion by I/O 2026. Enterprise generative AI spend followed the volume, not the price: USD 1.7B in 2023, 11.5B in 2024, ~37B in 2025, per Menlo Ventures. Only the frontier resists the trend: premium reasoning tiers still price output in the USD 25-50 per million range, as the pricing snapshot further down shows.
Three forces drive the volume, and each changes the shape of the bill, not just its size:
- Reasoning. Models emit long internal chains of thought, billed as output but never shown. Tokens processed per visible output token roughly tripled (from 12 to 36), so headline price cuts such as o3's 80% reduction understate what a task actually costs.
- Agents. One request becomes a multi-step loop that re-reads a growing context, calls tools, and retries. A five-step agent is rarely 5x a chat call; because context accumulates it is often an order of magnitude more, and agentic coding can consume ~1,000x a single chat turn. Agents the main driver of an estimated 14x annual volume growth.
- Caching. Prompt caching arrived across Google, Anthropic, and OpenAI, converging on ~90% discounts for cache hits. It is the main structural counter-pressure, but it only rewards workloads with stable, reusable prompt prefixes.
The net trend: cheaper tokens, radically more of them, and a mix getting both more output-heavy (reasoning) and more input-heavy (agents, long context), with caching the one lever pushing back.
Production workloads are billed in metered tokens, and the meter that grows the bill is also what makes it governable. Raw tokens are a billing unit, not a unit of value, so "which model is cheapest per token" stops controlling the bill. What controls it is workload shape: tokens per task, cacheable share, reasoning overhead, and whether the task even needs a frontier model. That is why self-host-versus-API is a portfolio management question, not a pure listing price question.
When to consider self-hosting
That said, almost nobody should self-host to save money on their first AI pilot. It becomes worth serious consideration when at least one of five conditions is true:
| Trigger | Why it matters | What to test |
| Data cannot leave a controlled environment | GDPR, contractual confidentiality, sector regulation, trade secrets, or board risk appetite may rule out external APIs. | GDPR, contractual confidentiality, sector regulation, trade secrets, or board risk appetite may rule out external APIs. |
| High-volume and repetitive workload | Small models can beat larger ones when the task is narrow, measurable, and stable. | Task-level evals, confusion matrix, human review rate, token volume, cacheability, drift. |
| Task benefits from specialization | Fine-tuned SLMs can replace frontier calls for extraction, classification, routing, template filling, narrow generation. | Labeled examples, distillation set, LoRA vs full fine-tune, regression suite, rollback path. |
| Latency or availability needs private control | Some workflows need predictable throughput, local fallback, or independence from provider incidents. | Latency SLO, queueing model, failover target, batching strategy, on-call ownership. |
| Building a platform, not one app | Shared infrastructure lets many workflows reuse routing, caching, evals, observability, and governance. | Platform team capacity, Kubernetes/ML platform maturity, security review, model-update process. |
The most common mistake is evaluating self-hosting at the model level instead of the workload-portfolio level. A EUR 200M industrial firm with one internal chatbot should not self-host a 70B model to save tokens. A EUR 1B insurer with several high-volume document workflows, strict data policies, and a cloud platform may reach the opposite answer.
The rented-capacity view: Neo clouds, capacity planning and LLMOps
When the choice is to rent hardware on a hyperscaler or a Neo cloud, besides GPU rental self-hosting total cost of ownership (TCO) analysis needs to include idle headroom for latency and burst; redundancy and failover; serving-stack maintenance (vLLM, SGLang, TGI, plus CUDA drivers, tokenizers, quantization); observability; security (IAM, isolation, secrets, audit logs); evaluation and regression testing; data-platform integration; on-call ownership; and procurement/compliance work (DPAs, subprocessors, residency).
Economically speaking renting can be favorable because someone else owns the hardware and carries the depreciation risk. The TCO estimates below are for the rented-capacity case.
| Self-hosted option (rented capacity) | Monthly TCO | Intended reading |
| SLM on existing platform | USD 1.3k | Spare platform capacity; limited HA burden. |
| SLM production HA | USD 3.8k | Small GPU footprint plus basic production ops. |
| 20B-32B production HA | USD 8k | Private assistant tier, more serving complexity. |
| 35B-A3B MoE production HA (e.g. Agents-A1) | USD 8k | 35B weights but ~3B active/token: near-32B memory, ~3B-active compute, single high-memory GPU feasible. |
| 70B/120B production HA | USD 22k | Large private serving, serious utilization and ops. |
| GLM-5.2-class single non-HA | USD 35k | Long-context serving without full redundancy. |
| GLM-5.2-class production HA | USD 75k | High-memory multi-GPU serving with redundancy and upgrade burden. |
These are planning bands – not quotes – anchored against current (July 2026) GPU cloud pricing adjusted for operational overhead. Real economics depend on region, contract terms, reserved capacity, utilization, latency SLO, team composition, and existing platform maturity.
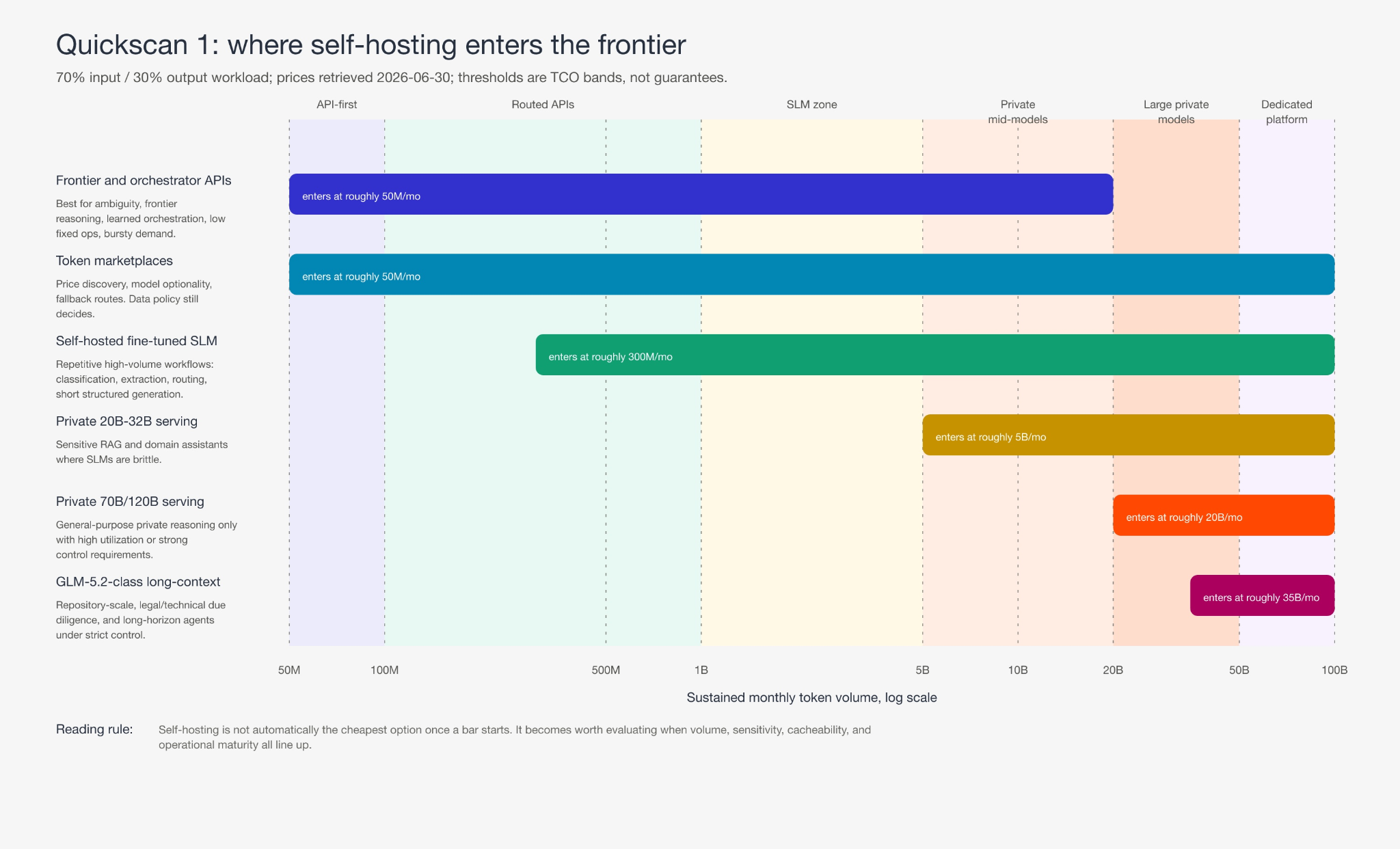
As a first-cut posture by monthly volume for one stable workflow:
| Monthly tokens | Default posture |
| < 100M | Don't self-host for cost. Only if data cannot leave the environment. |
| 100M-1B | Routed APIs and marketplaces. Look for one repetitive, measurable, confidential task to carve out for a fine-tuned SLM (a compact 1B-8B model tuned for a narrow job). |
| 1B-5B | Self-hosted SLMs are interesting for stable classification, extraction, triage, and structured generation. |
| 5B-20B | Private 20B-32B serving can enter the frontier, especially sensitive RAG and internal assistants. |
| > 20B | 70B/120B and GLM-5.2-class serving can be rational, usually for control, latency, resilience or residency as much as price. |
The owned-capacity view: purchased GPUs and depreciation
The moment you consider buying GPUs, the question changes shape. Purchase looks like the most procurement-flavored decision in the stack, yet the owned-capacity math proves it is still portfolio management: a bought GPU is a fixed cost that only earns its keep if a portfolio of models and agents keeps it busy.
To ground the owned case, let’s borrow the reference model Azeem Azhar's Exponential View team published in The State of the AI Economy 2026: a full 1 GW of AI capacity costed with Epoch AI's cost of ownership (May 2026) and SemiAnalysis token-output assumptions (FP4, 8k-in/1k-out, 50 tok/s/user, 65% utilization). It is hyperscaler-scale, but normalized it gives us a defensible floor for what a token costs to produce on owned silicon.
All-in annualized cost to own and operate 1 GW is ~USD 7.9bn per year, split 89% capital (servers, network, and facility on 6-to-14-year depreciation schedules) and 11% operating (energy, staff, maintenance). At 75-85 quadrillion tokens per GW per year, that is roughly USD 0.09-0.11 per million tokens at the 6-year base case: the ~USD 0.10 headline. Two adjustments matter:
- Licensing. Open-weight models carry no license fee, so the floor stays near USD 0.10/M. A closed-weight model licensed for self-serving adds a fee: a ~25% license fee on a Kimi K2.5-class blended price of USD 1.29/M adds ~USD 0.32/M, lifting the floor to ~USD 0.42/M. Owning hardware does not escape the model vendor's margin unless the weights are open.
- Depreciation is the dominant lever. How long you depreciate the GPUs, not how cheaply you buy them, sets the floor. Re-annualizing IT equipment across a 3-to-9-year life (14-year building constant) swings production cost from ~USD 0.16/M to ~USD 0.07/M, a 2.2x swing on the same hardware.
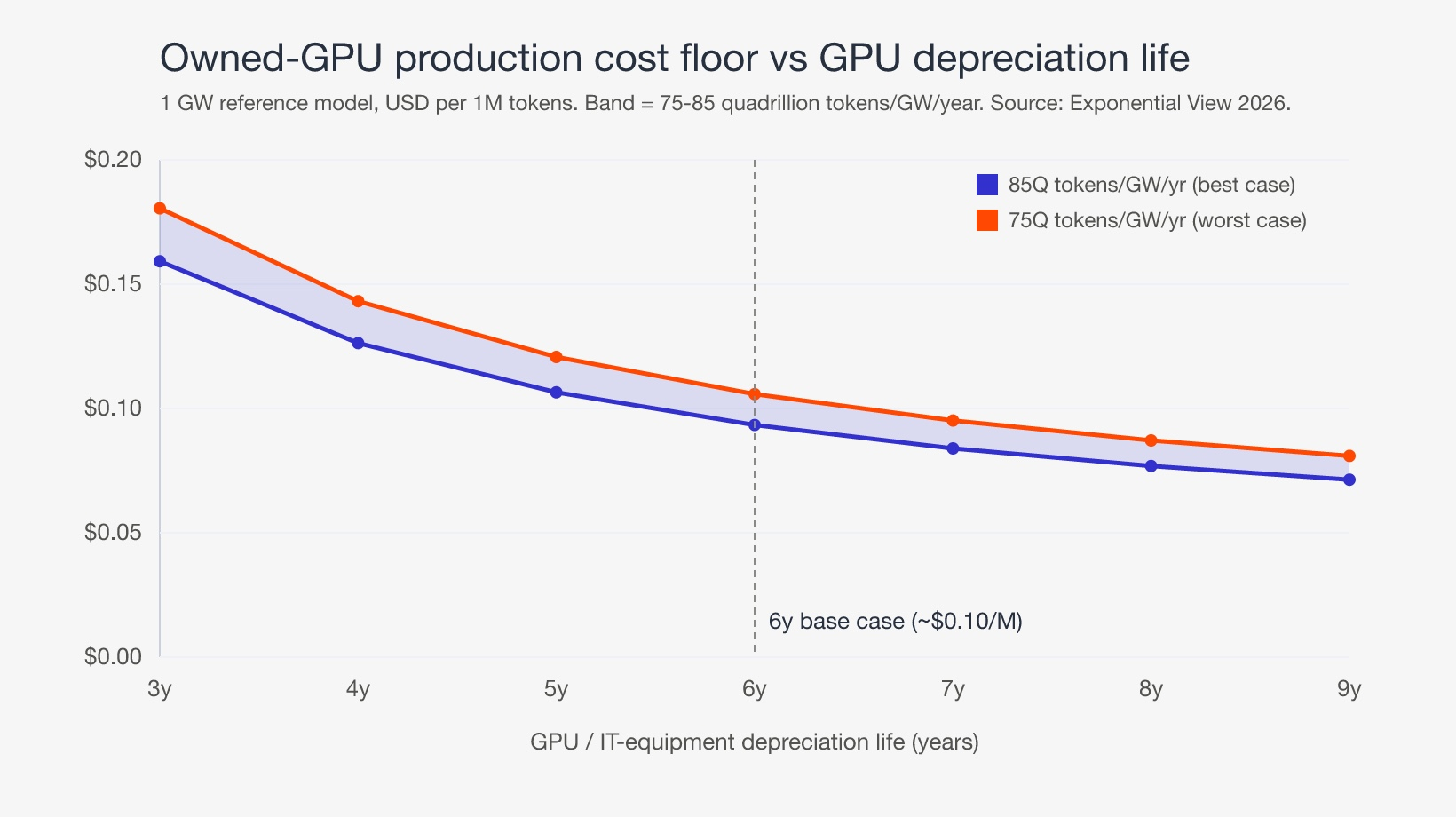
This is the same sensitivity the Exponential View team flags at industry level: infrastructure revenue headroom is ~19% at a 6-year chip life and ~36% at 8 years. Longer life is where payback lives, and shorter-than-expected life (obsolescence from a faster next-gen part) is the single biggest risk to an owned-hardware case.
Two conclusions follow, both pointing toward portfolio management, not procurement:
- The owned floor explains why ultra-cheap marketplace routes are so hard to beat. A blended gpt-oss-120b route near USD 0.066/M sits below the ~USD 0.10/M owned-cost floor: open-weight models at hyperscaler scale, high utilization, favorable depreciation, thin margin. A mid-market buyer with a handful of GPUs cannot reproduce that cost base.
- The reference economics are a best case that a midsized company will not hit. Normalized, the model implies ~USD 16,500 per GPU/year, ~USD 1.19M per NVL72 node/year, ~167 billion tokens per GPU/year at 65% utilization. One node loses bulk pricing, a hyperscaler's cost of capital, 65% fleet utilization, FP4, and speculative decoding, so realized cost is a multiple of the floor. A single owned model serving one company's bursty workload sits idle most of the day, and idle owned GPUs are the most expensive tokens in this analysis.
That is the crux of the shift. Renting matches spend to workloads, so procurement framing survives. Owning inverts it: the only way to make fixed, paid-for capacity economically viable is to drive utilization up by routing many models and agents onto the same hardware. The owned-GPU question is not "which model do we buy a box for" but "is our portfolio dense enough, and our routing good enough, to keep bought silicon busy across a realistic depreciation life." If not, rent, build the portfolio and routing layer first, and revisit ownership once utilization is provable.
The Pareto frontier: no single best model
Once the workload portfolio is on the table, model choice stops being a ranking exercise.
The picture that emerges is a frontier with at least five axes:
- Token unit cost: input, output, cached tokens, batch discounts, fixed capacity.
- Model capability: instruction following, reasoning, tool use, long context, language coverage, vision, video, speech generation, domain fit.
- Control: sovereignty, residency, auditability, fine-tuning, observability, lock-in.
- Operations: serving, upgrades, security, monitoring, evals, incident response.
- Latency and availability: interactive SLOs, burst, batch/offline, regional routing.
The frontier is jagged because model quality is task-local. One model dominates on price for public summarization but loses on confidential extraction; another dominates on hard reasoning but is wasteful for ticket routing; a third is cheapest in a marketplace but unacceptable because its logs or subprocessors do not fit policy.
Current (July 2026) token price snapshot
Selected 70/30 (input/output) blended prices, USD per 1M total tokens. That mix is a reasonable assistant/agent default, not universal: RAG is more input-heavy; drafting, code, and agentic loops are more output-heavy, and the frontier moves materially with the mix.
| Option | Input | Cached input | Output | Blended no-cache |
| OpenAI GPT-5.5 | 5.00 | 0.50 | 30.00 | 12.500 |
| OpenAI GPT-5.6 Terra | 2.50 | 0.25 | 15.00 | 6.250 |
| OpenAI GPT-5.6 Luna | 1.00 | 0.10 | 6.00 | 2.500 |
| Anthropic Claude Fable 5 | 10.00 | 1.00 | 50.00 | 22.000 |
| Anthropic Claude Opus 4.8 | 5.00 | 0.50 | 25.00 | 11.000 |
| Anthropic Claude Sonnet 4.6 | 3.00 | 0.30 | 15.00 | 6.600 |
| Google Gemini 3.5 Flash | 1.50 | 0.15 | 9.00 | 3.750 |
| Google Gemini 3.1 Pro | 2.00 | 0.20 | 12.00 | 5.000 |
| OpenRouter GLM-5.2 | 0.95 | 0.18 | 3.00 | 1.565 |
| Sakana Fugu Ultra | 5.00 | 0.50 | 30.00 | 12.500 |
| OpenRouter Llama 4 Maverick | 0.15 | n/a | 0.60 | 0.285 |
| OpenRouter gpt-oss-120b | 0.03 | n/a | 0.15 | 0.066 |
Caveats worth carrying into any decision:
- Frontier vendors ship tiered families, not single flagships (OpenAI GPT-5.6: Sol/Terra/Luna; Anthropic: Fable/Opus/Sonnet/Haiku), so the right tier per task matters as much as the vendor.
- Long-context requests carry premiums (GPT-5.5 roughly doubles input and adds 50% to output above ~272k tokens; Gemini still tiers by context length), so retrieval-heavy work sits on a steeper curve than this 70/30 snapshot.
- OpenRouter is a market snapshot, not a commitment: good for price discovery and fallback, but every production use needs data, provider, logging, and availability review. EU teams that need residency have OpenRouter-shaped alternatives (Requesty, EUrouter, Eden AI, Opper) that add EU hosting, low or zero retention, and a DPA; the catch is that the cheapest breadth often routes to US-hyperscaler EU regions, which buys residency but not sovereignty. For the latter, route to EU-owned providers (Mistral La Plateforme, Scaleway, OVHcloud, IONOS, Aleph Alpha) or self-host.
- Sakana Fugu Ultra is an orchestration example, not a plain open-weight comparator.
- USD list prices shown; for EU budgeting convert at current FX and add VAT, support, and commitment discounts.
Break-even is not one number
self-host break-even tokens/month = monthly self-hosting TCO / provider blended price per token
In practice the optimal answer is a surface, not a threshold, moving with input/output mix, cached share, latency SLO, utilization, batchability, and operational maturity.
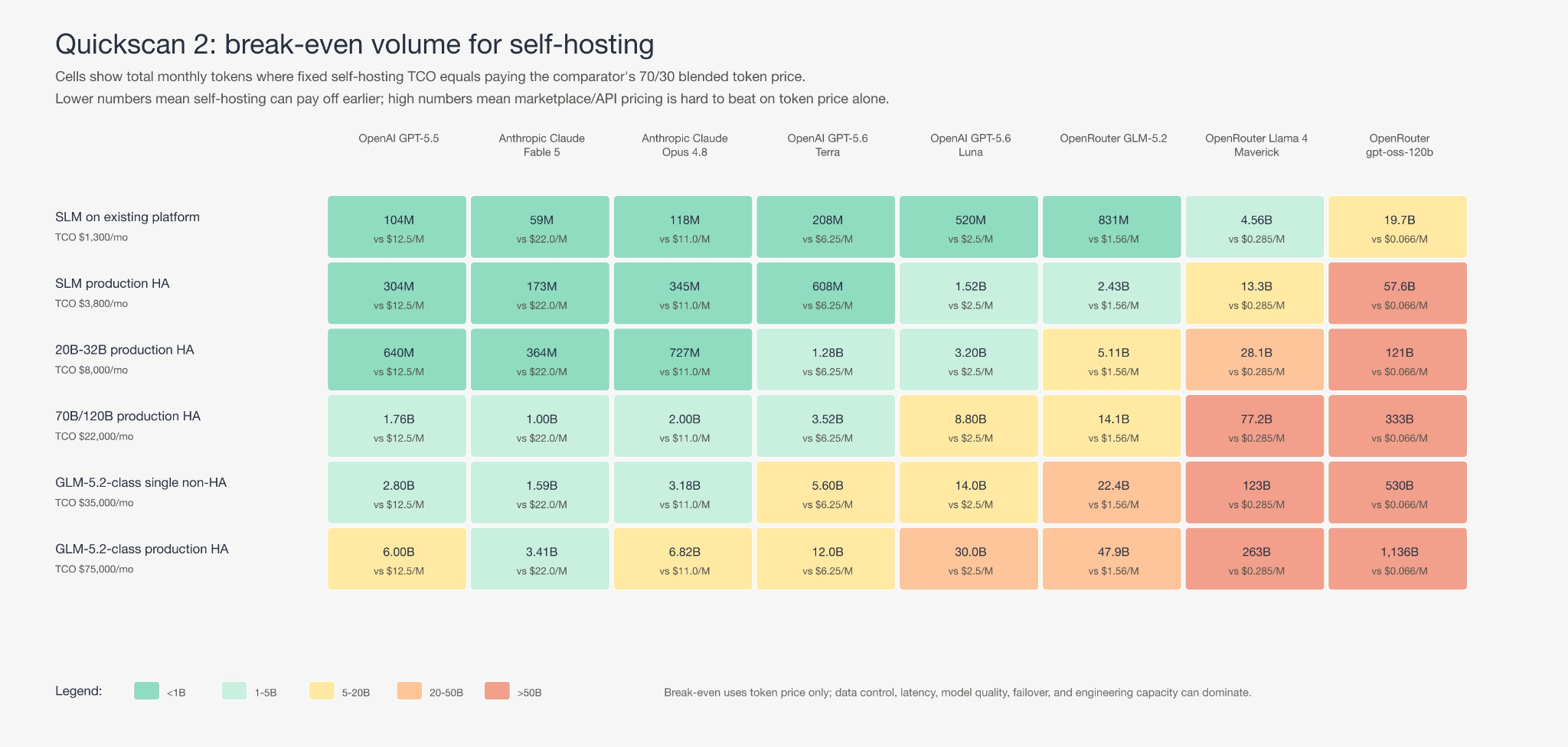
Two anchors can help frame your decision. A production small-model stack at USD 3.8k/month breaks even against a flagship API such as GPT-5.5 near 300M tokens/month, and the flagship tier (GPT-5.6, Fable 5) is now more expensive per token than the prior generation, so that break-even lands earlier for frontier models. Against an ultra-cheap marketplace route such as gpt-oss-120b, the same stack needs more than 50B tokens/month. The GLM-5.2-class HA line is not a mid-market default: it needs very high-volume long-context work, or sovereignty, latency, auditability, or tool integration as the real driver. Commercially speaking:
Self-hosting small specialized models can beat frontier APIs surprisingly early. Self-hosting large general-purpose models rarely beats marketplace prices on token cost alone.
That does not make self-hosting large private models irrational.
It does mean that the business case must name the control premium explicitly.
GLM-5.2 and the long-context tier
To add to this, GLM-5.2 tempts buyers for the wrong reason. The Z.ai/Hugging Face card positions it as a flagship long-context model (1M-token window, MIT license, vLLM and SGLang serving paths); OpenRouter listed it at USD 0.95/M input, 0.18/M cached, 3.00/M output on 2026-06-30.
One way to approach integrating these OSS models in your portfolio would be to
- Use marketplace GLM-5.2-style endpoints to learn whether long context actually improves the workflow.
- Not jump to self-hosting this tier for price alone – it rarely pays off.
Consider private GLM-class serving only when value comes from repository-scale context, legal/technical due diligence, high-sensitivity documents, agent traces, local tool integration, or strict residency.
A 35B-A3B counterexample: when the easy-to-deploy model wins
But not every capable model demands the GLM-5.2 serving tier. Agents-A1 (Apache-2.0, Shanghai AI Lab's InternScience, late June 2026, on a Qwen3.5-35B-A3B base) reports frontier-comparable quality for a mid-market footprint. On self-reported data, benchmarked against GPT-5.5 (xhigh), it wins on agentic search and tool use (Seal-0: 56.4 vs 42.3; GAIA: 96.0 vs 87.4), matches instruction following (IFEval: 94.8 vs 93.4), and losses on browsing and scientific coding (BrowseComp: 75.5 vs 84.4; SciCode: 44.3 vs 56.1).
Read it as comparable on agentic, scientific, and instruction-following work, not a blanket frontier replacement, and treat the numbers as self-reported until independent evals land.
Yet here the deployment gap against GLM-5.2 runs entirely in the smaller model's favour:
- Memory. 35B weights are ~70GB at BF16, ~35GB at FP8, ~20GB at 4-bit, so a single high-memory GPU (one H100/H200 80GB, or a 48GB card quantized) serves it, versus GLM-5.2's high-memory multi-GPU node. That is the ~USD 8k vs USD 35-75k/month gap: a 4-9x serving-cost swing before any utilization argument.
- Compute per token. The MoE activates only ~3B of 35B parameters per token, so throughput and latency behave closer to a 3B dense model, and interactive SLOs are easier to hit on modest hardware.
- Operational surface. Single-node serving removes multi-GPU failure modes, NVLink sensitivity, and cross-GPU sharding. Both expose OpenAI-compatible endpoints on vLLM and SGLang; Agents-A1's is one box, not a cluster.
GLM-5.2 still wins on context (1M tokens vs ~256K-262K), so for workloads that genuinely need a million tokens the heavier tier has a role. For the far more common confidential, high-volume workflow that fits in a few hundred thousand tokens, a 35B-A3B model is the more rational first target. And for many clients the first self-hosted win is not GLM-5.2 at all: it is a fine-tuned 1B-8B model that removes millions of repetitive frontier calls from a workflow with clear evaluation criteria.
Sakana Fugu and learned orchestration
Fugu from Sakana AI is a clear signal of where the market is moving, reinforcing the portfolio view advocated throughout this write-up. It is a learned multi-agent orchestrator: a model that decides how to combine specialist agents, tools, and model calls rather than answering directly. OpenRouter listed Fugu Ultra at USD 5/30/M (~USD 12.50/M blended), in line with the GPT-5.5 flagship and much more expensive than most direct routes. That only makes sense if orchestration quality reduces total work, lifts success rate, or handles tasks single-model routes cannot. The canary pattern for enterprise architecture:
- The routing layer gets more intelligent over time; some routes optimize for model quality, others for workflow completion rate.
- Compare total task cost, not token cost. A 20-step agent that succeeds once can beat a 5-step agent that fails three times and escalates to a human.
- Orchestration still needs enterprise controls: allowed tools, data boundaries, budget caps, evals, audit logs, human approval for high-impact actions.
This meshes with what we see in practice – most business value in production systems comes from orchestrated workflows, not isolated chat completions.
Routing and caching change the frontier
So in 2026 the smart choice is no longer “which model to use”. It’s to invest in building a control plane. Here it important to distinguish between two types of routing:
- Agent orchestration and routing (front-of-house). Decides which agent handles a task: intake, decomposition, assignment to a specialist agent or workflow, tool permissions, human checkpoints, budget caps. It reasons about tasks, not models.
- LLM routing (backend). Decides which model serves a given call: tier, self-hosted SLM vs private open-weight vs frontier API vs marketplace, caching, fallback, provider allowlists.
An agent selected by the agent gateway can make many model calls, each routed by the second. Keeping them separate lets each evolve independently: swap a backend model without touching orchestration, re-assign tasks without re-plumbing providers. Collapsing them into one "smart gateway" will make routing unmaintainable and un-auditable.
Routing should be intelligent, and intelligent does not mean LLM-based. A per-request LLM classifier adds latency and cost to every step, and is hard to make deterministic or evaluate. Routing can also be done with lightweight ML classifiers (task type, sensitivity, complexity, language) that run in single-digit milliseconds, retrain cheaply on your own traffic, and give you auditable decisions, reserving LLM judgement for the few cases they flag as ambiguous.

In addition, caching often moves the frontier more than a model swap. Exact prefix caching is high-confidence: structure stable system prompts, tool schemas, policy, catalogs, repo summaries, and RAG templates as reusable prefix blocks (vLLM does this automatically for self-hosted serving; frontier and marketplace routes have provider-specific economics). Semantic caching can save more but is a governance feature, not just an optimization: fine for FAQ-like service, policy explanations, and product metadata, dangerous for legal, financial, security, user-specific, or fresh-data workflows unless bounded by similarity thresholds, freshness checks, tenant isolation, and readable cache-hit logs.
A quickscan before you commit to self-hosting
This quickscan should prevent two failure modes: over-engineering a private model platform too early, and sending sensitive high-volume workflows to APIs forever because nobody modeled the frontier.

Business-case checklist
| Question | Green signal | Red signal |
| Task stable and measurable? | Clear labels, acceptance criteria, regression data. | "General intelligence" with no eval set. |
| Monthly token volume material? | Hundreds of millions for one workflow, or a path to billions across a portfolio. | One pilot chatbot, low sustained usage. |
| Output share high? | Long outputs, code, report drafting, agentic loops. | Short answers, cheap small-model API alternatives. |
| Context cacheable? | Stable policy, schema, catalog, repo, or regulatory prefix. | Highly personalized, constantly changing prompts. |
| Can an SLM replace larger calls? | Classification, extraction, routing, triage, templated generation. | Open-ended reasoning, ambiguous success criteria. |
| Budget owner for the control premium? | Security, compliance, ops, or product can name the value of private control. | "Open source should be cheaper" is the only argument. |
GDPR and EU AI Act checklist
Not legal advice, but the right engineering checklist before routing data to any provider, the kind of review ML6's AI governance practice runs with clients.
| Area | Questions to answer |
| Data classification | Personal, special-category, trade secrets, credentials, contracts, or regulated data in the prompt? |
| Legal basis and purpose | Is processing purpose clear, documented, compatible with original collection? |
| Processor chain | Which model provider, marketplace, cloud, logging, and observability vendor can see the data? |
| Residency and transfers | Where are prompts, completions, embeddings, traces, logs, and fine-tuning data stored and processed? |
| Retention | Are prompts and outputs retained, for how long, can a tenant delete them? |
| Automated decisions | Could the system materially affect employment, credit, insurance, healthcare, legal position, or access to services? |
| EU AI Act classification | Prohibited, high-risk, GPAI integration, or lower-risk assistance? What documentation and monitoring follow? |
| Auditability | Can you reconstruct which model, prompt, retrieval context, tools, cache hit, and human approval produced an outcome? |
The jagged frontier
As discussed, model quality is task-local: a fine-tuned small model can beat a frontier model on one extraction task and fail badly on an adjacent reasoning task. That is why the routing matrix above triages by task family and data sensitivity rather than by model.
Two rules of thumb: classification, extraction, and routing workloads move to self-hosted SLMs earliest, because they are measurable and stable; anything touching legal, financial, or safety outcomes stays human-gated no matter how good the model looks in a demo.
Team, MLOps, and LLMOps checklist
Self-hosting is production software, not procurement.
The minimum capabilities you will need are:
- Model serving: vLLM/SGLang/TGI, quantization, tokenizer compatibility, batching, prefix caching.
- Platform ops: Kubernetes or managed ML platform, GPU scheduling, image builds, driver/CUDA lifecycle, rollback.
- Evaluation: golden datasets, task metrics, human review loops, regression gates, red-team cases.
- Observability: prompt/response traces, token accounting, latency, cache-hit rate, route decisions, tool calls, retrieval context, error budgets.
- Security: tenant isolation, IAM, secrets, network controls, encryption, audit logging, retention/deletion.
- Governance: model cards, risk assessments, approved-provider list, DPIA support, human escalation policy.
- FinOps: per-tenant cost allocation, budget limits, cache savings, API-vs-self-host comparison, utilization reporting.
- Incident response: queue buildup, hallucinated high-impact content, provider outage, model regression, prompt-injection exposure.
If you don’t have an in-house team that could own these items, you’re probably not ready to start hosting your own models yet. We can of course help you get started.
How to start
The safest path is not to choose the model first. Start with the workload portfolio.
Step 1: instrument current and planned usage. For each workflow, measure or estimate monthly input/output/cached tokens, batch-vs-interactive split, latency and availability requirements, data classification and residency, current and fallback routes, quality target and human-escalation rate, cacheable prefixes, and expected growth over 6/12/24 months. Build a token ledger. Without it, every self-hosting discussion becomes ideology.
Step 2: build an evaluation harness. Create task-specific evals: representative examples from the client's own domain; outputs scored against business outcomes; separate metrics for factuality, extraction accuracy, refusal behavior, tone, latency, and cost; regression tests for prompt, routing, model, and fine-tune changes; human review where automated metrics are weak. This is where the jagged frontier becomes visible: some workflows collapse neatly into an SLM, others show frontier reasoning is still worth the price.
Step 3: introduce a routing and caching control plane. Use a gateway before committing to infrastructure: normalize requests into task types, classify sensitivity, apply tenant policy, route by quality/cost/latency/availability/approval, use exact prefix caching for stable blocks and semantic caching only for low-risk repeated answers under eval and audit control, and log every route decision, cache hit, model/prompt version, retrieval context, and cost. LiteLLM-style routing, OpenRouter-style provider routing, and in-house policy services are all patterns for this layer. The point is separating application logic from model procurement.
Step 4: integrate where the tokens are actually spent. A company can build an elegant gateway and still miss the heaviest users if the tools where people spend tokens do not route through it. This matters most for software engineering, where coding assistants are right now often both the highest-value and highest-volume LLM surface, but integration models differ sharply:
- Application services, internal agents, and backend copilots can be pointed at a gateway from day one.
- Claude Code explicitly supports LLM gateways for centralized credentials, usage tracking, cost controls, and provider switching. The caveat is feature pass-through: the gateway must forward the API features it expects.
- OpenCode is structurally friendlier to custom routing (OpenAI-compatible providers, custom baseURL, custom headers, explicit models), a better fit when coding agents should consume models through your own gateway.
Cursor is a very strong DX product but centered on its own Auto/Composer pools and Premium/API routing, so enterprise gateway control and open-weight routing need verifying against the actual plan. - Codex has a local OSS lane via --oss and local providers (LM Studio, Ollama), useful for experimentation but not a centrally governed enterprise routing layer.
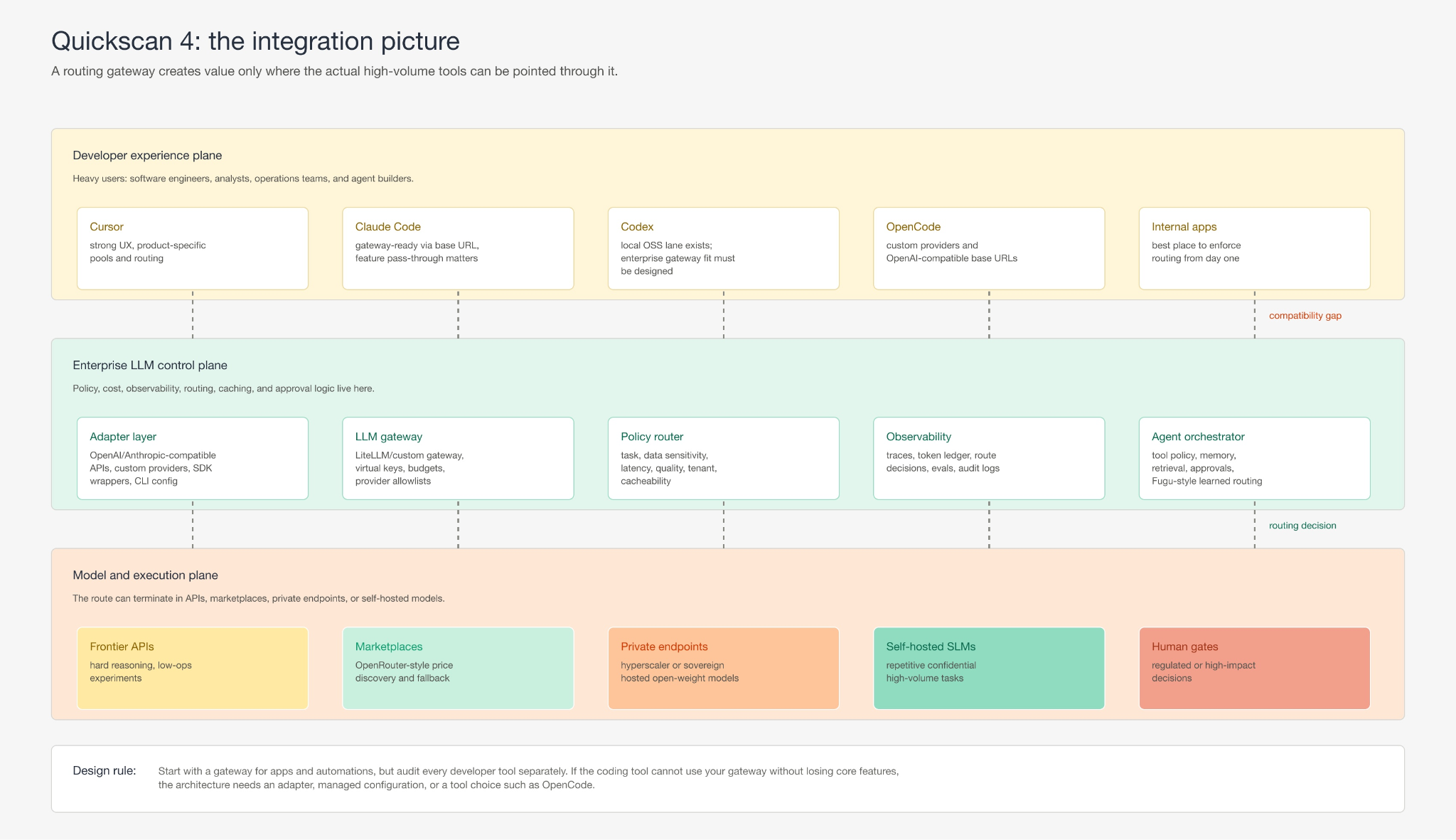
The practical result is an integration ladder:
| Integration pattern | Best fit | Constraint |
| Direct gateway integration | Internal apps, automations, agent backends, SDK services. | Application teams must adopt the gateway API and observability conventions. |
| IDE/agent gateway mode | Claude Code-style or OpenCode-style custom providers. | Validate streaming, tool calls, caching, model naming, context limits, feature pass-through. |
| Product-native enterprise plan | Cursor-style managed tools, Copilot-style procurement, vendor cloud agents. | Faster adoption, less control over routing, caching, substitution, data plane. |
| Local OSS developer lane | Codex --oss, LM Studio, Ollama, offline experiments. | Good for sovereignty experiments, weak for governance, cost accounting, team evals. |
| Wrapper or sidecar | CLI tools, CI agents, custom workflows. | Adds engineering burden, can break when the underlying tool changes. |
This is to avoid scenarios in which the optimal unit economics sit behind a gateway but developer adoption runs inside a proprietary coding tool. Decide where the routing layer should own the user experience and where it needs to integrate with a vendor interface: reach the interfaces people actually use.
Step 5: choose the gateway deployment pattern. Once integration surfaces are clear, choose the topology where cloud strategy and user experience meet:
| Deployment pattern | Good fit | Watch out for |
| Custom centralized gateway | Multi-model routing, developer enablement, provider abstraction, custom audit. | You own the API contract, docs, streaming, schema translation, lifecycle. |
| Azure APIM + Azure AI Foundry | Azure-first orgs wanting managed auth, policy, cost, safety, agent runtime. | Best when already aligned with Azure identity, networking, governance. |
| Google Cloud glass-box routing | GCP clients wanting a universal API over Vertex AI, Gemini, Claude, open-weight backends. | Gateway must handle schema translation and stay observable. |
| AWS custom gateway | AWS-first clients on Bedrock, VPC, Lambda, DynamoDB, ECS/Fargate. | REST patterns awkward for streaming; ECS/Fargate + ALB or Lambda web adapters may be needed. |
| Off-the-shelf AI gateway | Fast rollout of virtual keys, routing, budgets, rate limits, logging. | Must support the exact tools, streaming, tool calls, caching, governance hooks needed. |
Two design choices matter early:
- invoke vs converse gateway. invoke accepts free-form requests (flexible, easy, but leaves responsibility in every app); converse exposes opinionated task interfaces (less flexible, more platform control over routing, logging, policy, safety, evals). Most start with invoke for adoption and move selected workflows to converse, because repeatability is what enables governance and cost optimization.
- When traffic may bypass the gateway. Overhead is negligible interactively, but high-throughput batch may need a direct private endpoint. Make the exception explicit: a bypassing workload still needs equivalent logging, cost allocation, evals, and data controls.
Strategically, gateways are about guiding the flywheel as much as they are about cost control: one place to onboard teams, manage credentials, swap models, enforce policy, measure quality and spend, and turn successful patterns into reusable platform capabilities.
Step 6: carve out one SLM candidate. The first self-hosted model should be boring: a repeated extraction workflow, a compliance/quality tagging task, a customer-service intent classifier, a document triage model, or a narrow structured-generation task. Run it as a controlled replacement: use the frontier model to generate or validate training data, fine-tune or distill the SLM, evaluate offline against held-out examples, deploy in shadow mode, then split limited traffic before making it the production route with a frontier fallback.
If the SLM handles 80% of a repetitive workflow at acceptable quality, the frontier model becomes an escalation path instead of the default cost center.
Step 7: evaluate private large models. Private 20B-32B, 70B/120B, and GLM-5.2-class deployments come after the control plane and eval harness exist, otherwise the company buys GPUs before knowing which tasks need them. Use them when sensitive context rules out API routes, volume can fill the capacity, latency and availability can be engineered, the model is shared across workflows, the team can operate the serving stack (or has a managed partner), and the value of control justifies a premium over marketplace prices.
Vendors and stacks to look at
The right list depends on cloud strategy, data classification, and procurement constraints.
Here is a layered shortlist:
- Hyperscaler / managed cloud: Azure (AI Foundry, Azure ML, AKS), Google Cloud (Vertex AI, GKE, TPU/GPU), AWS (Bedrock, SageMaker, EKS, EC2 GPU) – all of which are ML6 technology partners we can help you onboard or self-host LLMs on.
- Sovereign / EU infrastructure: Scaleway and OVHcloud (French), Nebius (Amsterdam HQ, EU capacity), other specialist GPU providers and Neo clouds, and client-owned/colocation for strictest sovereignty. Confirm region, legal entity, and subprocessor chain.
- Owned-hardware purchase (only after the owned-capacity math above works; depreciation matters more than sticker price): NVIDIA (GB200/GB300 NVL72, HGX B200, DGX) default, AMD Instinct (MI325X/MI350) main open alternative, Intel Gaudi / Cerebras / Groq for narrow latency-critical work; OEM servers (Dell, Supermicro, HPE, Lenovo); colocation (Equinix, Digital Realty) or client-owned facility; VAR/SI/leasing to smooth CapEx, weighed against debt on hardware a next-gen part has made uneconomic.
- Model and marketplace: OpenAI, Anthropic, Google for frontier reasoning (all three are ML6 technology partners); OpenRouter for price discovery, fallback, and orchestration routes like Sakana Fugu Ultra; Mistral, Z.ai/GLM, Qwen, Llama, DeepSeek, and gpt-oss families depending on license, quality, footprint, and governance.
- Serving and LLMOps: vLLM or SGLang for high-throughput serving and prefix caching; Hugging Face TGI where ecosystem fit matters; a LiteLLM-style or custom gateway; OpenTelemetry-compatible tracing plus LLM-specific cost/latency/eval observability; a human escalation workflow.
- Gateway deployment: Azure API Management + AI Foundry; Google Cloud API Gateway + Vertex AI; AWS Bedrock/API Gateway/Lambda/VPC/ECS/Fargate/ALB; LiteLLM, ORQ-style, or custom gateways where multi-provider routing, virtual keys, budgets, and onboarding matter most.
The target end state we recommend is the two-gateway reference architecture shown earlier: applications and IDEs enter through agent orchestration, every model call passes through LLM routing, and observability spans both. ML6's role here is not reselling one model, but designing the workload taxonomy, evals, routing policy, private deployment pattern, portfolio management, AI governance frameworks and LLM operating model.
Bottom line
For both mid-market and enterprise clients self-hosting is most attractive when it is specific: specific workload, data-control requirement, token volume, latency SLO, evaluation target, and team ownership.
Which means that the Pareto-optimal answer is usually a model portfolio. Keep frontier APIs for hard reasoning, research, innovation and fast experimentation. Use marketplaces for price discovery and burst capacity where data policy allows. Self-host fine-tuned SLMs for repetitive, sensitive, high-volume work. Move to larger private open-weight models only when volume, operational maturity, or sovereignty need justifies the premium.
The cheapest model on a pricing page is rarely the cheapest production system. The cheapest production system is the one that routes each task to the least expensive model that still satisfies quality, latency, security, sovereignty, and governance.
How ML6 can help
Most organizations do not need a model recommendation. They need an LLM operating model: how to decide which tasks deserve which models, which data can go where, how quality is measured, and when automation should stop. ML6 builds that layer end to end.
LLM routing quickscan. ML6's AI advisory team maps your workload portfolio against the frontier: token volume and mix per workflow, GDPR and EU AI Act risk profile, candidate routes (SLM, open-weight, frontier, marketplace, human-gated), developer-tool integration, self-hosting TCO bands, and the first business case likely to pay back. The output is a decision map: which workloads stay on frontier APIs, move behind a gateway, get tested through marketplaces, or become self-hosting candidates.
One thing to keep in mind: computer agents like Claude Cowork, Codex, and Antigravity are putting a frontier model on every marketing, service, operations, legal, and finance user's machine, not just developers'. Non-engineering token spend is on track to match or exceed engineering spend within the next few years, so you need to size routing, governance, and TCO for that population before the bill arrives, not after.
Intelligent routing and caching control plane. ML6's AI engineering team builds the two-gateway control plane: agent orchestration with tool permissions, budget caps, and human checkpoints; LLM routing across frontier APIs, marketplaces, private endpoints, and self-hosted models; lightweight-ML routing instead of an LLM in the hot path; exact-prefix and eval-governed semantic caching; and observability with regression gates for every prompt, model, fine-tune, and policy change. This is also where Fugu-style learned orchestration comes in: valuable, but only inside guardrails on tools, data exposure, spend, and human approval.
Agent orchestration for production workflows. For clients moving beyond assistants into operational agents, ML6's agentic AI practice designs the workflows themselves: decomposition and agent roles, tool integration with permissions and audit trails, retrieval and memory, human checkpoints for regulated actions, and evaluation of task completion rather than answer quality, deployed on hyperscaler, sovereign, or client-controlled infrastructure. The goal is not a clever demo but a governed execution layer where each step runs on the cheapest capable model, under the right data boundary, with measurable outcomes.
If you want to map your own workload portfolio against the evolving frontier, talk to ML6.
Sources
Token-usage and cost trends (volatile, retrieved 2026-07-01):
- Exponential View, The State of the AI Economy 2026 (Azeem Azhar et al.), "Tokens" chapter: global volume >30 quadrillion/month at ~14x YoY, blended price USD 17 to USD 2 vs Epoch Capabilities Index 112 to 158, price-elasticity ~1.2-1.8, tokens-per-output-token 12 to 36, total vs output token growth (+39x vs +30x, Jan 2025-Apr 2026), revenue per GW >USD 7bn, and the token-based-pricing "pay-per-click" framing. Retrieved from reports/ev-state-of-ai-economy-2026.pdf on 2026-07-01.
- a16z, "Welcome to LLMflation" (10x/year inference cost decline): https://a16z.com/llmflation-llm-inference-cost/
- Epoch AI, LLM inference price trends (9x-900x/year, median ~50x, ~200x since Jan 2024): https://epoch.ai/data-insights/llm-inference-price-trends
- Google I/O 2026 token volume (~3.2 quadrillion tokens/month, ~7x YoY), via The Register: https://www.theregister.com/ai-ml/2026/05/19/google-touts-tokenmaxxing-huge-capex-and-ai-agents-at-i/o/5242983
- Menlo Ventures, 2025: The State of Generative AI in the Enterprise (USD 1.7B/11.5B/37B enterprise spend 2023-2025): https://menlovc.com/perspective/2025-the-state-of-generative-ai-in-the-enterprise/
- Artificial Analysis, o3 pricing and reasoning-token economics: https://artificialanalysis.ai/models/o3
- "Tokenomics: Quantifying Where Tokens Are Used in Agentic Software Engineering" (arXiv): https://arxiv.org/html/2601.14470v1
- Microsoft Research / Stanford, "How Do AI Agents Spend Your Money?" (per-task token consumption in agentic coding): https://www.microsoft.com/en-us/research/publication/how-do-ai-agents-spend-your-money-analyzing-and-predicting-token-consumption-in-agentic-coding-tasks/
- PromptHub, prompt caching across OpenAI, Anthropic, and Google (caching timeline and ~90% cache-hit discounts): https://www.prompthub.us/blog/prompt-caching-with-openai-anthropic-and-google-models
- Communications of the ACM, "Tokens Are a Utility" (Jevons paradox framing): https://cacm.acm.org/blogcacm/tokens-are-a-utility-were-treating-them-like-software/
Pricing and model data:
- OpenAI API pricing: https://platform.openai.com/docs/pricing
- Anthropic Claude pricing: https://docs.anthropic.com/en/docs/about-claude/pricing
- Google Gemini API pricing: https://ai.google.dev/gemini-api/docs/pricing
- OpenRouter model pricing endpoint: https://openrouter.ai/api/v1/models
- GLM-5.2 model card: https://huggingface.co/zai-org/GLM-5.2
- Agents-A1 model card (35B-A3B MoE, Apache-2.0, ~256K-262K context, vendor-reported GPT-5.5(xhigh) benchmarks; self-reported, retrieved 2026-07-02): https://huggingface.co/InternScience/Agents-A1
- Agents-A1 project page and serving instructions (vLLM/SGLang, OpenAI-compatible endpoint): https://internscience.github.io/Agents-A1/
- Sakana Fugu technical report: https://arxiv.org/abs/2606.21228
GPU and infrastructure anchors:
- Exponential View, The State of the AI Economy 2026 (Azeem Azhar et al.): owned 1 GW reference model, Epoch AI cost of ownership (May 2026), SemiAnalysis InferenceX token output (April 2026), and CapEx depreciation-schedule sensitivity. Retrieved from reports/ev-state-of-ai-economy-2026.pdf on 2026-07-01.
- Runpod pricing: https://www.runpod.io/pricing
- Lambda GPU Cloud pricing: https://lambda.ai/service/gpu-cloud/pricing
- Scaleway GPU pricing: https://www.scaleway.com/en/pricing/gpu/
- OVHcloud GPU and AI infrastructure: https://www.ovhcloud.com/en-ie/public-cloud/gpu/
- Nebius pricing: https://nebius.com/prices
Routing, caching, and serving:
- vLLM automatic prefix caching: https://docs.vllm.ai/en/latest/features/automatic_prefix_caching.html
- LiteLLM routing: https://docs.litellm.ai/docs/routing
- LiteLLM proxy quick start: https://docs.litellm.ai/docs/proxy/quick_start
- OpenRouter provider routing: https://openrouter.ai/docs/features/provider-routing
- Claude Code LLM gateways: https://code.claude.com/docs/en/llm-gateway
- OpenCode providers: https://opencode.ai/docs/providers/
- Cursor models and pricing: https://cursor.com/docs/models-and-pricing
- Codex CLI local help checked with codex --help on 2026-06-29.
Regulatory background:
- GDPR text: https://eur-lex.europa.eu/eli/reg/2016/679/oj
- EU AI Act text: https://eur-lex.europa.eu/eli/reg/2024/1689/oj
- European Commission AI Act overview: https://digital-strategy.ec.europa.eu/en/policies/regulatory-framework-ai


