Executive Summary
The assassination of Olof Palme remains one of the most extensive criminal investigations in modern European history. With over 250 meters of archived police material and thousands of digitized case files, the 34 years long Swedish police investigation generated a dataset too vast for any individual to fully process.
In collaboration with Softwerk and investigative journalists from Spår, ML6 built PalmeNet-Chat 2.0: a Deep Research AI agent system deployed on Google Cloud. By combining Retrieval-Augmented Generation (RAG), hybrid vector and keyword search, and multi-agent workflows, the system enables structured analysis of large criminal investigation archives. And all those additions were implemented in just 4 days!
The solution demonstrates how AI agents can support document-heavy investigations by navigating fragmented evidence, cross-referencing hypotheses, and accelerating research across thousands of files.
The journalists at Spår have a proven track record of re-opening cases based on their investigation. Will AI applied on the police archive lead them to find new links on the Olof Palme case?
Applying AI Agents to the Olof Palme Murder Investigation
Recent advances in Large Language Models (LLMs) have made it possible for AI agents to sift through massive amounts of unstructured text. It started with retrieval-augmented generation (RAG), but today’s autonomous agents can go much further — investigating hundreds of hypotheses, validating facts, and cross-referencing competing theories on their own.
Criminal investigations are a natural fit for this kind of technology. Reports pile up over decades, and no single investigator can absorb an entire case archive — let alone one the size of the Olof Palme investigation.
What makes this project particularly compelling is that it brings together one of the biggest unsolved mysteries in modern history, exclusive data, and cutting-edge agentic AI technology.
This post covers:
- The case
- The collaboration behind PalmeNet-Chat
- Data Layer: The Digitised Police Archive
- AI Agentic Workflows Implemented
- Google Cloud Architecture and Engineering
- The Palme Chat Application & Results
- Contact & credits
The case
Olof Palme was the acting Swedish Prime Minister when he was assassinated on the streets of Stockholm in 1986. To this day, the killer and motive have not been identified.
The investigation that followed is one of the largest in history.
The assassination of Olof Palme took place in central Stockholm on Sveavägen Street, shortly after he left a cinema with his wife. The crime scene investigation generated extensive witness descriptions, forensic evidence, and follow-up leads that shaped the Swedish police investigation for decades (Reuters).
Over time, several investigative theories were explored, including a possible link to the Apartheid regime in South Africa (retaliation for Palme’s anti-apartheid stance) and suspicions involving the PKK (amid tensions between Sweden and Kurdish militants at the time). In later stages of the investigation, attention increasingly centered on a domestic suspect known by the pseudonym the “Skandia Man”.
In the words of the Swedish police:
" The murder shook Sweden and the investigation lasted for just over 34 years. It is by far Sweden’s largest and perhaps the world’s most extensive and has generated several hundred metres of material such as witness interviews and investigation documents. The investigation is comparable in size to the investigations into the Lockerbie bombing and the assassination of John F Kennedy."

“250 metres of material.” That’s rows upon rows of files, still sitting in the police archive today (Sveriges Radio).
The investigation pursued leads ranging from individual suspects to international organisations, from the PKK (classified as a terrorist group in Sweden) to the South African Apartheid regime, since Palme was one of the most prominent international voices against apartheid at the time.
In June 2020, prosecutors officially closed the case, naming the “Skandia Man” as the most likely perpetrator. But the evidence against him was circumstantial, and since Engström had died in 2000, he could never be charged.
In December 2025, the Director of Public Prosecutions went a step further and withdrew Skandia Man’s designation as the main suspect, deeming the evidence too weak. The case remains formally closed, but the debate is far from over, substantial new evidence could still lead to its reopening (Reuters).
The collaboration behind PalmeNet-Chat
This project was started by investigative journalists Martin Johnson and Anton Berg, creators of the podcast Spår.
Their first season tackled the Kaj Linna case. Kaj was serving a life sentence, but Martin and Anton’s investigation led to the reopening of the police inquiry, and eventually to Kaj’s release. The case made national headlines, and for good reason. Martin and Anton have a proven track record of finding what others miss.
Now they’re taking on the Palme case, which is another beast entirely. The archive is far too vast for a team of two to study in full. In fact, this was a fundamental limitation of the police investigation itself, no single person ever had the complete picture. Information is scattered across thousands of records, and connecting all the dots by hand simply isn’t feasible. This is where AI comes in.
Originally, Anton and Martin collaborated with Softwerk to build PalmeNet-Chat: a custom, fully on-premise AI environment that ingested the digitised police files, letting the journalists securely “converse” with the evidence (see article on PalmeNet-Chat 1.0).
In December 2025, ML6 joined the collaboration to build, jointly with Softwerk, PalmeNet-Chat 2.0. The application was moved to Google Cloud, the search engine was upgraded to Vertex AI Search, and the agentic workflows were enhanced with more sophisticated tools and larger LLMs. The ML6/Softwerk engineering team had four days to deliver it!
Data Layer: The Digitised Police Archive
The police began digitising their archive in 2020. In parallel, a crowd-sourced initiative called Palmemordsarkivet emerged to collect and organise investigation documents, and it remains active today.
Only about 10% of the total archive has been digitised so far. The police estimated that the full archive spans “250 metres of shelves of documents” (Sveriges Radio), which means even that 10% is enormous. It consists of roughly 3,700 PDFs, each between 10 and 400 pages, covering everything from police reports and prosecution data to images, maps, and sketches. Softwerk built an on-premise OCR and RAG pipeline to convert these scans into searchable text, the data foundation for everything that follows.
To put the scale in perspective: a Swedish state commission stated in 1999 that it would take 6-7 years for a single person to read through the entire police archive at the time. And the investigation went on for 21 years…
AI Agentic Workflows Implemented
This is where AI changes the game. We implemented three approaches of increasing complexity:
Agentic RAG
Agentic RAG is an evolution of Retrieval Augmented Generation (RAG). In a traditional RAG setup, a user asks a question, a retriever finds relevant documents, and an LLM generates a reply based on them. It works — but the retrieval step is fixed: one query per question, same parameters every time.
![Image: RAG architecture overview][img-rag-architecture]
AI agents change that equation. For a solid introduction to AI agents, see this blogpost from Anthropic. The key shift is giving an LLM not just context, but tools, and the autonomy to decide when and how to use them. Instead of a fixed retrieve-then-generate pipeline, the agent controls the search process itself. Our simplest agent system looks like this:
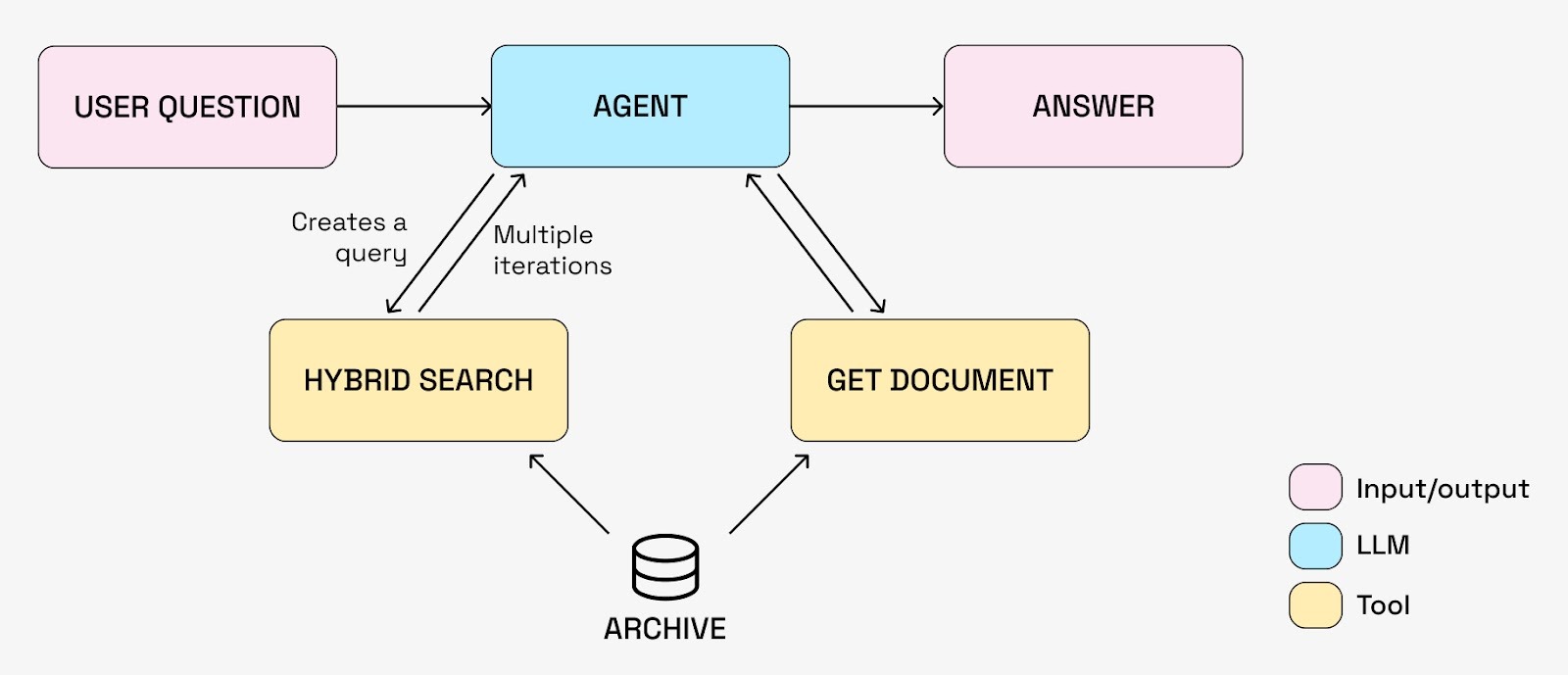
The agent has access to two tools:
- Hybrid search: queries the document archive using a combination of vector and keyword search, returning document fragments based on plain-text queries.
- Get document: fetches full documents by ID, since hybrid search only returns unordered chunks.
This autonomy matters because the agent can now decompose a single question into multiple targeted queries and iteratively chase leads. It finds something relevant, generates a follow-up query, digs deeper, exactly how you’d want an investigator to work.
On top of that, searching the archive is far from trivial. We built a custom hybrid search engine that combines keyword matching (exact terms, names, dates) with semantic search (matching on meaning). The archive combines highly different, rich and complex documents, across many different types of content, witness interviews, forensic reports, maps, prosecution data, each with their own metadata fields. Currently, we only have a single “general” search tool, but it could be extended to support more specific search queries (search for a specific person, date, document type, etc.).
Deep Research
The next step is to let multiple agents collaborate on a task, where each agent produces an output (for example, text) that gets passed to the next one.
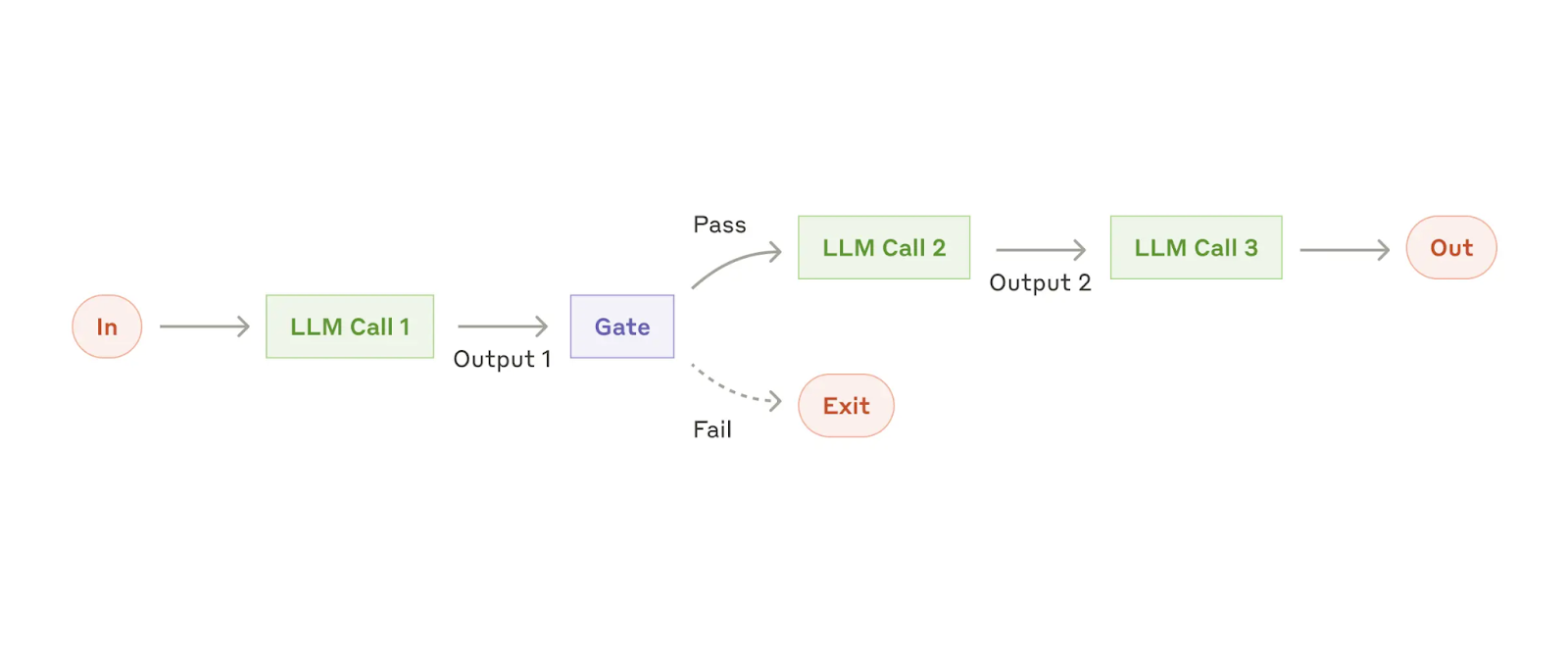
Sequential LLM pipeline with gating logic controlling whether outputs continue through additional processing steps.
A key example of this pattern is Deep Research. Multiple agents work together to find complex information in a database. What makes this powerful is that agents can reason about their approach, run a query, analyse the results, and then launch new queries based on what they found. This iterative loop can run several times before anything is shown to the user.
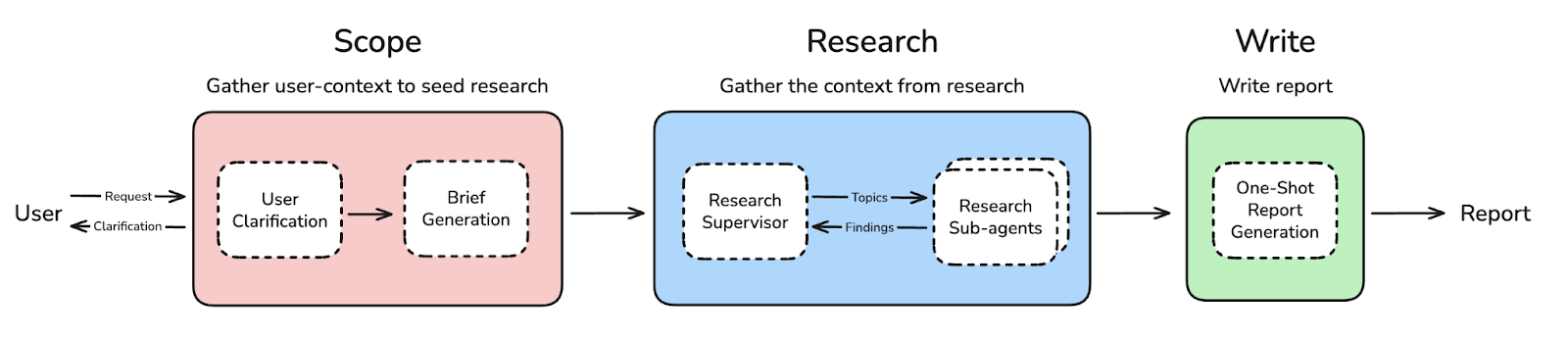
The figure above shows a generic Deep Research architecture, inspired by open_deep_research. Most of the “agents” here are really just LLM prompts. The Research sub-agents have access to a database — in our case, the one built on top of the digitised Palme archive.
Here is how we built it:
- An Orchestrator agent analyses the user query and breaks it into 1–5 research angles.
- For each angle, a dedicated Deep Researcher agent runs 3–5 unique searches in the database, each returning multiple documents.
- The results flow back to the Orchestrator, which decides whether the research is sufficient or needs to go deeper.
- If not sufficient, it identifies new angles and spins up additional Deep Researcher agents.
- If it is, it synthesises the findings into a final report.
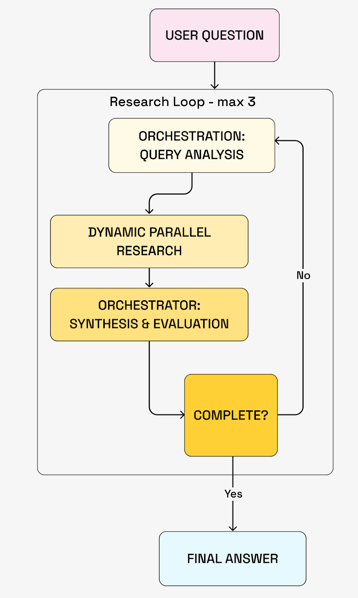
This flow is described in more detail in the following figure:

Multi-agent research loop where the orchestrator assigns research angles to parallel agents, synthesizes findings, and iteratively evaluates completeness before producing a final response.
Agentic Newsroom
A natural next step is to model the agentic workflow after real investigative journalism processes, mapping human domain expertise into AI workflows is a well-established best practice.
We sat down with the investigative journalists and co-designed an Agentic Newsroom workflow:

Agentic newsroom workflow translating investigative journalism into multi-agent AI coordination.
A lead investigator creates a list of hypotheses, and each one is assigned to a Team of Researcher Agents. These teams are Agent-to-Agent components where multiple agents discuss and evaluate possible leads together.
Google Cloud Architecture and Engineering
The Google Cloud application architecture looks as follows:

End-to-end Google Cloud architecture powering the deep research system, from archive ingestion to agent orchestration and user interface.
Here’s a breakdown of the key components:
- Digitised Archive: The starting point — scanned police report PDFs.
- OCR Pipeline: Converts the PDFs into text. This was built by Softwerk on a physical GPU using a mature set of open-source tools. It extracts named entities via NER, and a classifier tags each element (text, map, image, table) for specialised parsing. A multimodal LLM then generates a description of each document, helping downstream agents understand what they’re looking at.
- Translation: Since most of the archive is in Swedish, we translated everything to English using the Vertex Batch Inference API with Gemini models. Bilingual search was an alternative we considered.
- Vector Search DB: The parsed documents are ingested into Vertex AI Search, Google Cloud’s managed vector search offering. This is the hybrid search engine described above — supporting keyword and semantic search across multiple fields including document text, named entities, and document descriptions.
- Tools: Agents interact with the archive through tools, the main one being “Hybrid Search” for querying the vector database. These behave like MCP tools, though we didn’t end up using MCP — integrating a secured MCP server with Agno proved too much overhead given the four-day timeline.
- Agents: We built multiple agent workflows using Agno, a framework for building agents, equipping them with tools, managing memory and sessions, and orchestrating multi-agent flows. Frameworks like Agno (or alternatives such as LangChain and the OpenAI Agent SDK) offer a real head start, but can limit the degree of customisation possible. In our case, we ran into friction wiring secure MCP access to agents running in a separate microservice.
- API Layer: A REST API served from a single Cloud Run microservice.
- LLMs: The Gemini suite, used across all agents.
- Traces & Observability: We integrated LangFuse to inspect agent inputs and outputs within each flow, and to track costs — a critical consideration when running reasoning models in iterative loops.
- Conversation Storage: User conversations are persisted in Firestore, Google Cloud’s NoSQL document database.
- Experiments: Not all agentic workflows fit behind a simple API — some require complex inputs, produce rich outputs (like timelines), or take too long to run interactively. For those, we used dedicated Python scripts.
- Palme Chat Frontend: The user-facing application, built with Next.js and deployed on Firebase (more on this below).
Thanks to Softwerk’s earlier work on the OCR pipeline, the PalmeNet-Chat 2.0 implementation started from step 3. Everything from translation to the deployed frontend — steps 3 through 12 — was built in just four working days!
The Palme Chat Application & Results
The result of those four days is Palme Chat, a clean chat interface where users can ask questions and get answers grounded in the actual police archive.
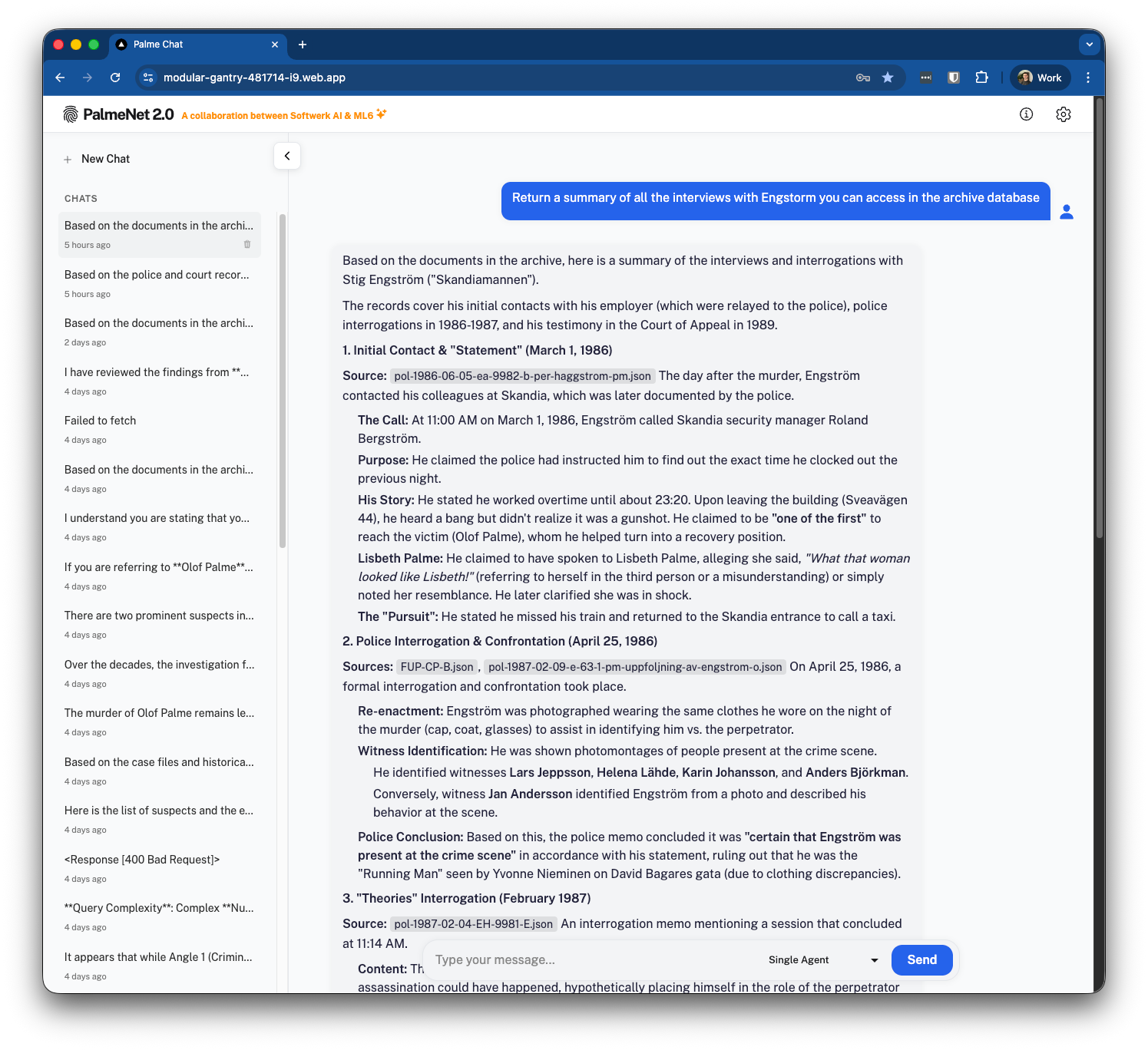
Palme Chat interface returning grounded responses sourced directly from the digitized police archive.
Since we implemented multiple agentic workflows, users can select which one to use for each request.
The single agent returns retrieved documents in a nicely formatted view, combining results from both the hybrid search and get-file tools.

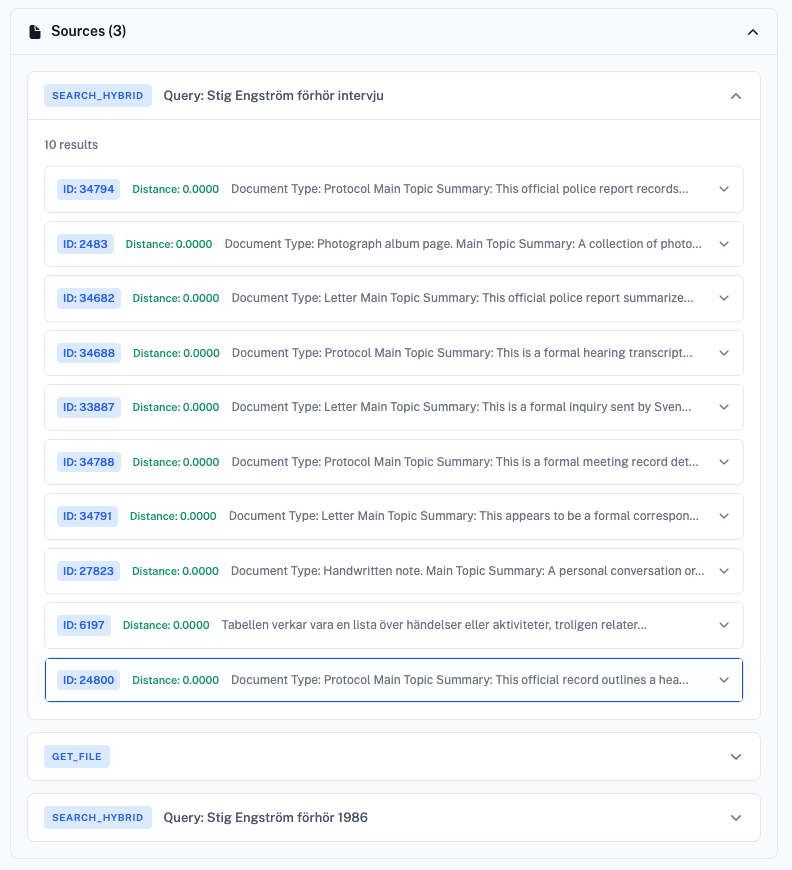
Notice how the agent constructs iterative queries. In this example, it likely found references to a 1986 interview during its first search, then automatically launched a follow-up query with “1986” explicitly included, chasing leads on its own.
Investigation team
Lead AI Architect
Thomas Vrancken
thomas.vrancken@ml6.eu
Engineering partners (Softwerk)
Tibo Bruneel
tibo.bruneel@softwerk.se
Bjorn Lundsten
bjorn.lundsten@softwerk.se
Investigative advisor
Martin Johnson
martin@martinjohnson.se
Journalistic collaboration
Anton Berg
anton.berg@me.com
Built by
- Sebastian Wekkamp
- Titus Nabber
- Hoshee Lee
- Jean De Smidt
- Kais Kermani
Massive thanks to everyone who helped build the application.
References
- Swedish police, Palme investigation overview
- Sveriges Radio, requests to access the Palme investigation
- Reuters, prosecutor review of the Palme case, December 2025
- Palmemordsarkivet, crowd-sourced digital archive
- ML6, leveraging LLMs on domain-specific knowledge bases (RAG)
- Anthropic, building effective agents
- LangChain, open_deep_research