

Executive Summary
As grid expansion struggles to keep pace with electrification, improving the utilization of existing infrastructure is becoming a strategic priority. This blog presents an operator-facing topology-optimization solution that combines multi-objective reinforcement learning with human-in-the-loop decision support, turning millions of grid configurations into ranked, explainable actions that relieve congestion while respecting reliability constraints. In benchmark simulations, the agent successfully completed 87% of 28-day episodes using topology actions alone, versus 65% for a greedy baseline. Building on ML6’s proven work in transformer hotspot modeling and system-imbalance forecasting, the approach demonstrates how AI can strengthen operational decision-making while keeping operators firmly in control.
The need to utilize the grid better
Demand for grid capacity is growing faster than the grid can expand, driven from both sides at once: volatile renewable generation feeding in on the supply side, and rapid electrification of transport, heat, and industry pulling on the demand side. The result is congestion. Congestion does not mean the grid is full. It is a geotemporal problem: in specific places and at specific peak moments, the local grid cannot carry all the electricity that wants to flow through it. That distinction matters, because it points to the opportunity. There is often capacity available, just not where and when it is needed.
Despite massive efforts to expand the electricity grid, congestion will persist for years. New cables, substations, and transformers are essential, but they take time to plan, permit, and build. The build-out itself is constrained by scarce people, materials, space, and execution capacity. Meanwhile, the impact is already being felt: electrification is stalling, delaying the shift to net-zero. The Netherlands is widely considered a leading indicator of grid congestion due to high renewable penetration and rapid electrification, and studies put a number on it: they estimate the societal cost at €10bn–€40bn per year, depending on scope and methodology [1].
Topology optimization can help grid operators make better use of existing infrastructure: safely, transparently, and without replacing human judgement.
The affordability challenge is just as urgent. The Netherlands faces an estimated €195bn in electricity infrastructure investment by 2040, including €107bn for the onshore grid. Building faster is unavoidable, but building alone is not enough. We also need to use the grid we already have more intelligently. The IBO estimates that additional choices to better use the onshore grid could reduce the cumulative investment challenge by €3.5bn–€22.5bn [1].
Market-based congestion management remains essential, but it is increasingly clear that it cannot be the only short-term lever. The main tools are curtailment, which cuts generation or offtake to limit power flows; capacity steering, which increases or reduces generation or offtake to actively counter power flows; and redispatch, which adjusts generation and load through balance-neutral countertrades after congestion is detected. Curtailment and capacity steering are typically scheduled day-ahead or at fixed moments; redispatch is applied intraday. In 2025, TenneT's regular congestion-management costs rose 42%, redispatch volumes increased 31% to 289 GWh, and GOPACS cleared less than 6% of TenneT's requested flexibility [2]. The flexibility market lever helps, but it is bounded by the amount of flexibility that can actually be found, contracted and activated.
That is where AI-enabled grid optimization becomes relevant. Better utilization can help operators unlock capacity sooner, reduce pressure on costly corrective measures, and make safer, faster decisions with existing infrastructure. In this blog, we focus on one underused lever for better utilization: topology optimization. It can redirect power flows through less-congested parts of the network, but the number of possible configurations is too large to assess manually in real time.
We explored how reinforcement learning, combined with a human-in-the-loop decision-support interface, can help operators navigate that complexity while keeping the final decision in human hands. The central question is: how can we make topology optimization usable for operators in real time, so it becomes a practical congestion-relief lever rather than a theoretical option?
One underused lever: topology optimization
What is topology optimization?
Transmission and distribution system operators (TSOs and DSOs) have several ways to create more room on the existing grid before new infrastructure is built: stretching technical asset limits, for example through dynamic line rating and dynamic transformer rating; routing power more intelligently through advanced power-flow control or topology optimization; and rethinking reserve capacity through curative N-1 policies, where part of today's static contingency reserve (held to keep the grid stable if any single component fails)— is made available under strict operational conditions. Studies suggest that selected measures can unlock capacity by tens of percent in specific grid contexts, depending on local constraints, reliability margins, and implementation conditions [3][4].
Topology optimization, as part of so-called Grid Enhancing Technologies (GET [5]), focuses on the second route: changing the configuration of the grid so that electricity flows through less congested paths. In practice, this means changing the network topology, for example by opening or closing breakers or reconfiguring busbars, so power flows are redistributed away from constrained assets and toward parts of the grid with more available headroom.
The appeal is clear. Topology actions have close to zero marginal cost in fuel, market payments, and new infrastructure. They do not require a new line to be built or a market party to be paid to move demand. But they are not risk-free. Switching consumes equipment cycles, changes power flows throughout the network, and must respect operating procedures, asset constraints, and reliability margins.
Why is topology optimization hard to use in practice?
On paper, topology optimization sounds straightforward: change the grid configuration so that electricity flows through less congested paths. In practice, every switching action is a system-wide intervention. Opening a breaker, closing a line, or splitting a busbar changes how power flows across the network, and those flows must still respect all operating constraints.
That is where the complexity starts. A topological action that relieves one overloaded line can increase loading somewhere else. It can improve thermal margins but create voltage issues. It can solve a local bottleneck but push more flow onto an interconnector where capacity is reserved for cross-border exchange or system balancing. And it must remain safe under N-1 conditions: if another component fails, the grid must still stay within its physical limits. The literature refers to this as the "competing optimizers" problem [6][7].
The search space is equally challenging. Topology optimization combines discrete decisions, such as breaker positions and busbar configurations, with continuous grid physics, such as generator voltage setpoints and power flows. In optimization terms, this becomes a large Mixed-Integer Non-Linear Programming (MINLP) problem. Classical numerical solvers can be accurate, but they are often too slow for real-time operations, especially when each new grid state requires a fresh calculation. In the control room, operators do not have hours. In stressed conditions, they may have minutes.
The human challenge is just as important. Operators understand that topology matters, but they cannot manually evaluate millions of possible configurations while also checking thermal loading, voltage, N-1 security, cross-border constraints, and operational procedures. The safe default is therefore to rely on known configurations, proven heuristics, and more tractable measures such as redispatch, curtailment, or market-based congestion management.
This is why topology optimization remains underused. The barrier is not awareness of the lever; it is the lack of a practical way to search the option space quickly, safely, and explainably. To become operationally useful, topology optimization needs a decision-support layer that can surface a small number of feasible actions, show their expected impact, and leave the final judgment with the operator.
The RL Agent: learning offline, advising in real time
Reinforcement Learning is useful here because it shifts the computational burden to the preparation phase. Instead of solving the full topology-optimization problem from scratch every time the grid state changes, the agent learns offline in a simulator. During training, it explores many grid situations, including severe contingencies, and learns which topology actions tend to keep the system within operational constraints. At runtime, the trained policy requires only a forward pass through a neural network, enabling it to propose candidate actions in milliseconds.
This does not make the AI an autonomous controller. It makes it an option generator. The model searches a space too large for manual exploration and surfaces actions worth considering; the operator remains responsible for the final decision. That distinction is central to the architecture: the goal is not to replace control-room judgment, but to give operators a richer, faster, and better-explained set of options.
We use Multi-Objective Reinforcement Learning because topology optimization is not a single-objective problem. A useful action must relieve congestion without creating unacceptable side effects elsewhere in the grid. In the current setup, the reward function combines two operational objectives: reducing thermal loading on internal lines and preserving interconnection capacity for cross-border balancing requirements. The same architecture can be extended with additional terms for voltage quality, N-1 security, switching costs, or asset health impact.
The agent is trained with Proximal Policy Optimization (PPO)[8], a policy-gradient method that directly optimizes a policy: a function that, for any given grid state, outputs a probability distribution over possible topology actions. This is different from value-based methods, which learn to score individual actions and select the highest-scoring one. For large, structured action spaces like topology switching, policy-gradient methods are better suited because they can generalize across the action space rather than evaluating each candidate exhaustively. What separates PPO from other policy gradient methods is that it updates its strategy in small, controlled steps, which keeps training stable and reduces the risk of the agent unlearning safe behavior when it meets a new scenario.
Reward shaping provides an additional training guardrail. Actions that worsen congestion, create illegal grid states, or lead to simulated failure are penalized immediately, so the agent learns to avoid unsafe parts of the action space. This is also where operational preferences can be encoded. Switching frequency can be treated as an explicit cost: every topology action changes the flow system-wide and carries operational risk, so the agent is encouraged to find stable configurations that hold for longer rather than reacting to each new grid state with a new switch.
Every recommendation should be presented with its expected before-and-after impact: which constraints improve, which constraints may worsen, what assumptions the estimate depends on, and how confident the system is. The operator can accept, reject, or modify the suggestion. In that setup, AI does not rewrite the control-room operating model; it strengthens it by making more feasible options visible in a timely manner.
What we built: an operator-in-the-loop decision-support prototype
We built a prototype decision-support system that makes the reinforcement-learning policy usable for operators. It searches the topology space at machine speed, identifies promising candidate actions, and presents clear before-and-after impact predictions so operators can inspect, challenge, and compare recommendations before deciding what to do.
At a high level, the architecture has five layers:
- Grid scenario input: The system starts from a grid state: topology, line and transformer loading, generation, demand, forecasted evolution, and relevant operational constraints.
- Simulation environment: We use Grid2Op [10] as the reinforcement-learning environment. Grid2Op models the grid as a dynamic system rather than a static planning snapshot: the agent observes the grid state, proposes topology actions, receives feedback, and continues through a time-series scenario. This allows us to test actions such as line switching and busbar splitting under changing demand and generation patterns.
- Power-flow validation: Grid2Op delegates the physical grid calculations to a backend solver. In our setup, we use LightSim2Grid [11] as the power-flow engine, a fast AC power-flow simulator purpose-built for reinforcement-learning environments. This ensures that candidate actions are evaluated against AC grid physics rather than treated as abstract graph moves, without becoming a runtime bottleneck during training. The agent does not simply learn what looks good mathematically; every proposed action is tested against the network's physical behavior.
- Multi-objective RL agent: The agent is trained with Proximal Policy Optimization (PPO) and a reward function that jointly optimizes thermal loading on internal lines and interconnection capacity. Reward shaping penalizes illegal actions and unsafe grid states. The architecture is extensible: voltage quality, N-1 security, and switching cost can be added as additional objectives.
- Human-in-the-loop interface: The decision-support interface is the operator-facing layer. It translates the agent’s output into ranked, explainable recommendations. For each proposed action, the operator can inspect the expected before-and-after effect on line loading, interconnection constraints, and grid stability. The operator can accept, reject, or modify the suggestion.
The result is a system architecture that separates learning, physics validation, and operational decision-making. The RL agent learns offline in simulation. Grid2Op provides the simulation environment, while LightSim2Grid is used as the fast AC power-flow backend. The interface exposes only the relevant recommendations to the operator. Final control remains with the human decision-maker.
The prototype has four practical views. A simulation view shows live grid state, suggested actions, and predicted impact. A model-comparison view shows how agents behave across scenarios. An action catalog lets users inspect the exact substations, breakers, and busbar changes behind a recommendation. A home view gives the overview and navigation.
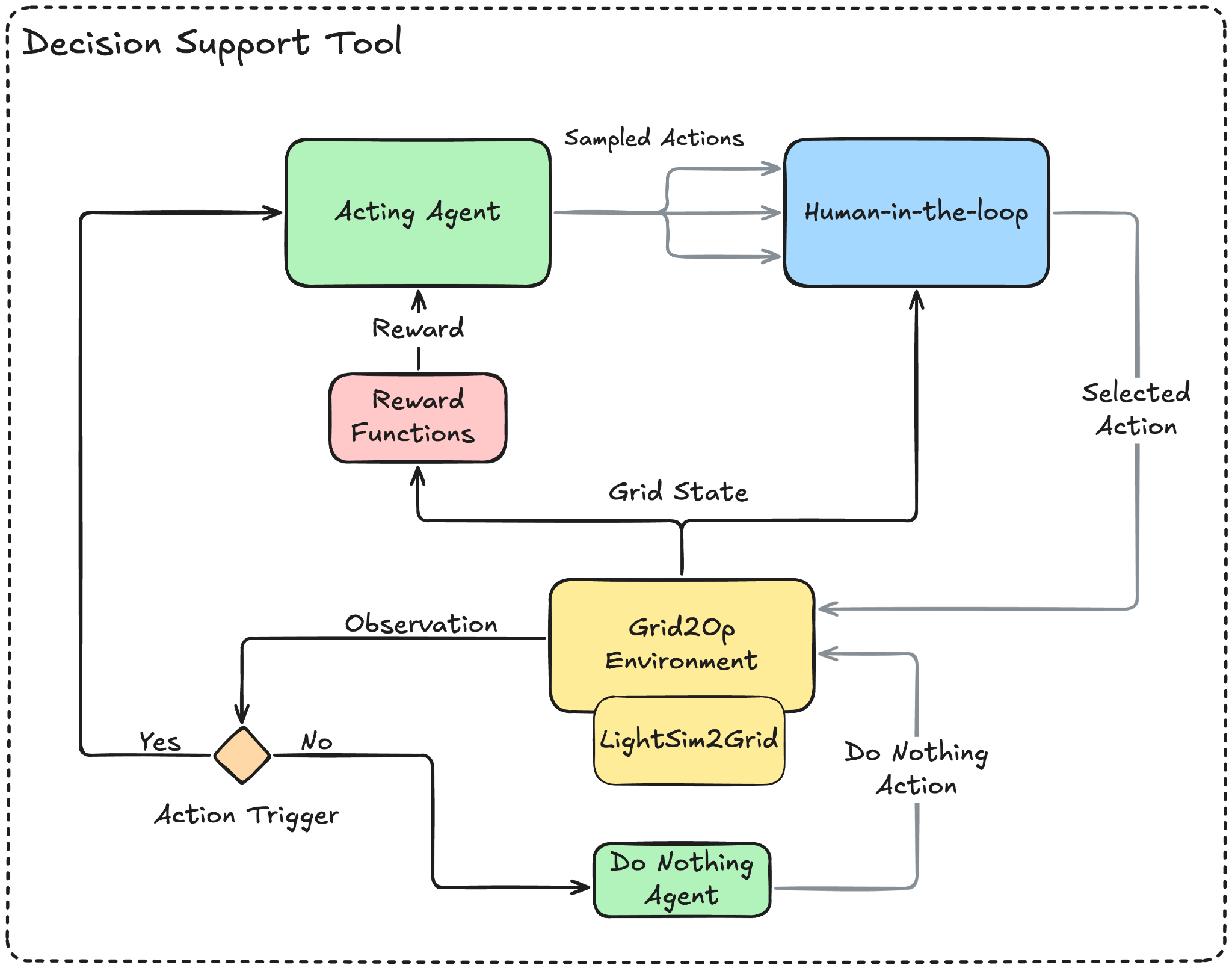
Figure 1. Decision Support Tool architecture, from grid scenario input to human-in-the-loop interface
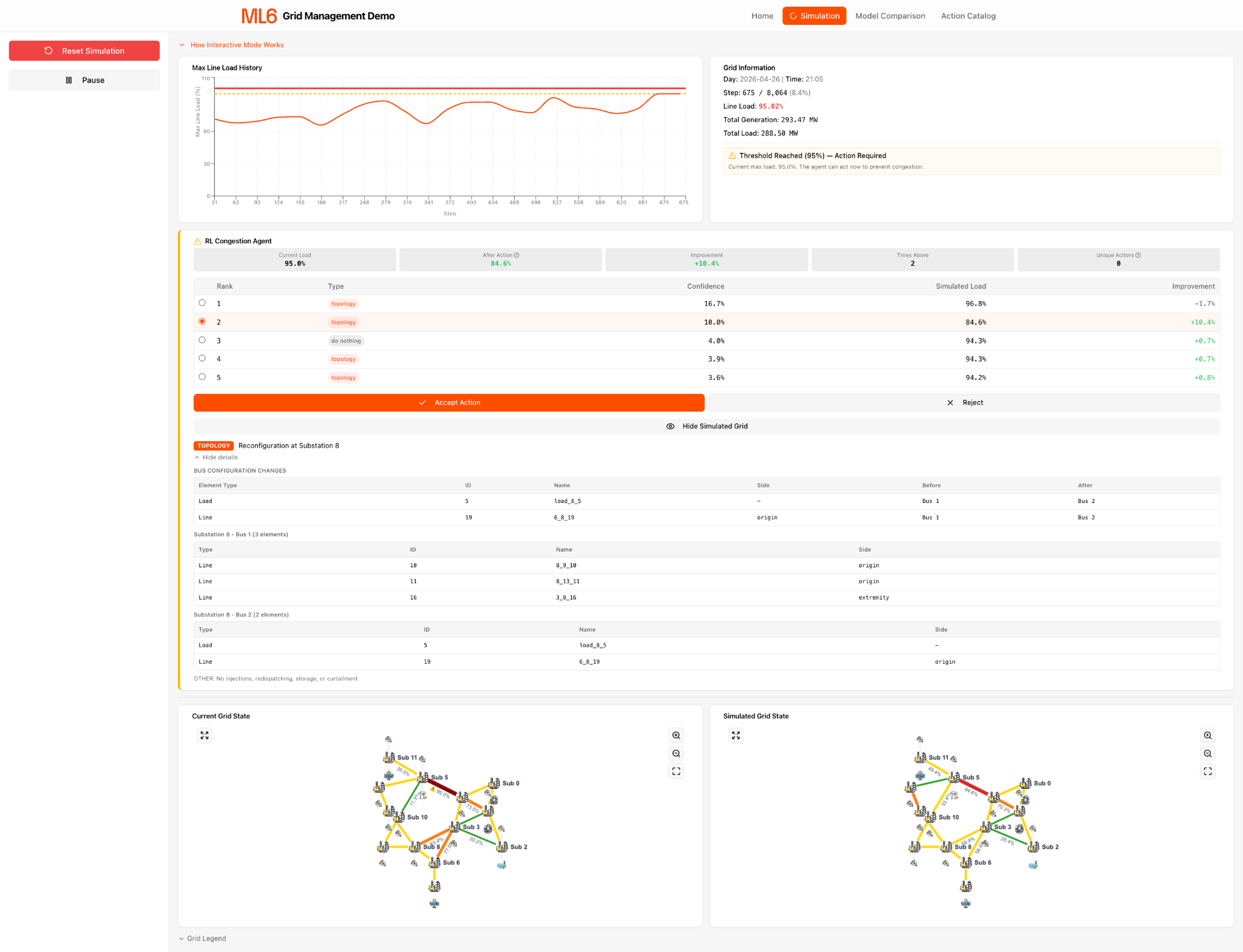
Figure 2. Simulation view showing live grid state, suggested topology actions, and predicted impact
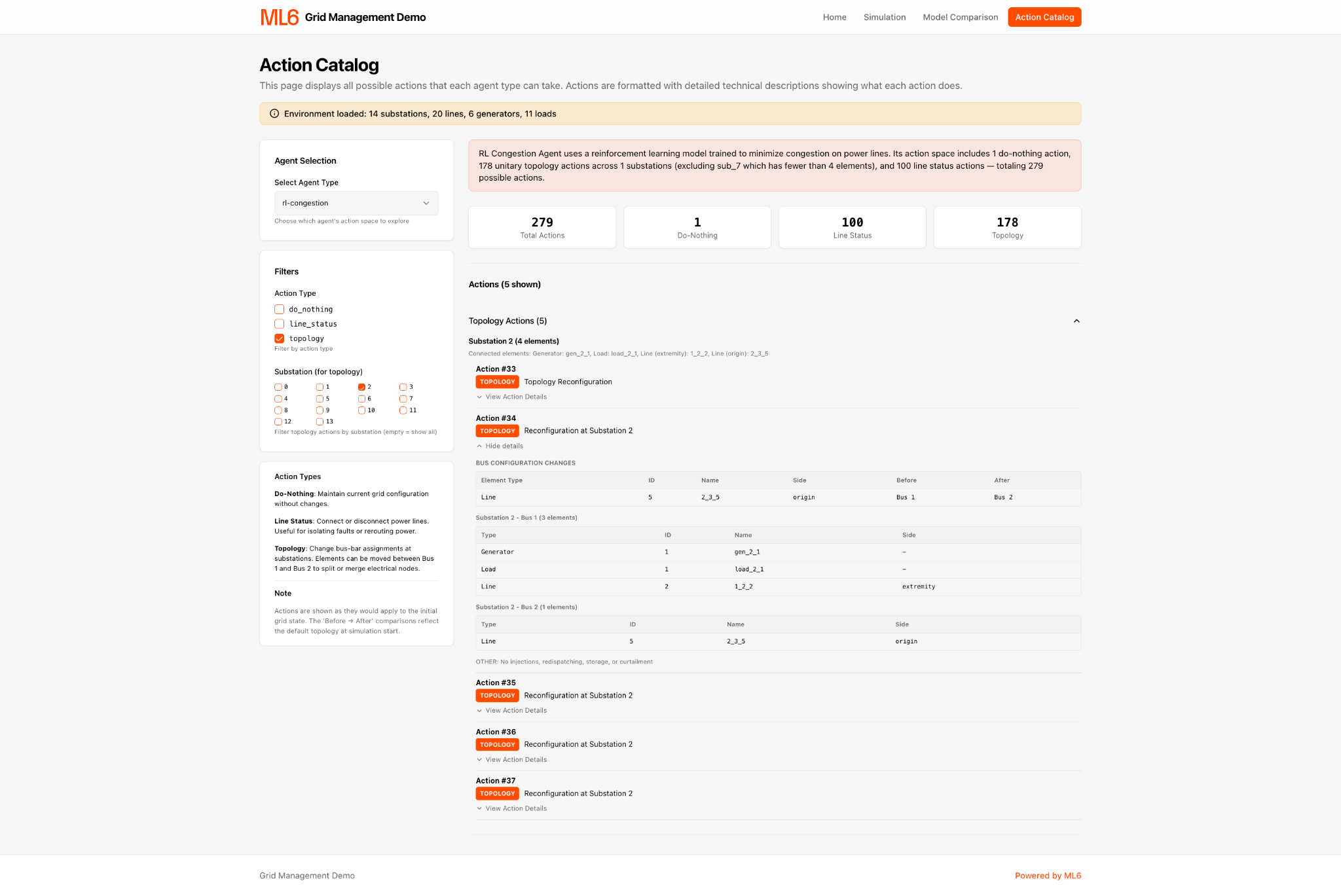
Figure 3. Action catalog view listing substations, breakers, and busbar changes behind a recommendation
What the results show
We evaluated the agent in the L2RPN Case 14 benchmark environment. This is not a customer-grid deployment but a controlled benchmark to test whether the approach can quickly search for topology actions and balance multiple operational constraints. We trained the agent for 1,000 iterations and evaluated on 28-day simulated episodes with a maximum episode length of 8,064 steps at 5-minute resolution. We ran the evaluation across 22 runs on Chronic IDs 0, 1, and 2.
We compared the RL agent against two baselines. The first is a Do Nothing policy, which takes no topology actions and shows where the grid fails without intervention. The second is a Greedy policy, which simulates available topology actions one step ahead and selects the action that minimizes immediate line loading. The Greedy policy is a strong short-term baseline, but it does not optimize for longer-term stability or multi-objective constraints.
Simulation overview
|
Metric |
Do Nothing |
Greedy policy |
RL acting agent |
|
Average steps survived |
1,037 |
6,879 |
7,355 |
|
Survival rate |
0.00% |
65.00% |
86.96% |
|
Average congestion events |
44.70 |
47.60 |
8.80 |
|
Standard deviation, steps |
1.03 |
2.07 |
2.01 |
Table 1. Simulation overview across 22 benchmark runs. Survival means reaching the final simulation step of the 28-day episode.
The main result is that the RL agent completed the full simulated episode in 86.96% of runs, compared with 65.00% for the Greedy baseline. This matters because the Greedy policy is not a weak comparator: it actively evaluates topology actions and selects the action that provides the best immediate relief. The RL agent performs better because it learns a policy that looks beyond the next step and favors configurations that keep the grid within limits for longer.
The second result is efficiency. The RL agent reduced the average number of congestion events from 47.6 to 8.8, an 81.5% reduction, while using far fewer switching actions: the Greedy policy takes more than 110 actions in some episodes, while the RL agent rarely exceeds 30 (Figure 4a). This reflects a qualitative difference in behavior. The Greedy policy reacts to the immediate grid state and switches frequently; the RL agent identifies higher-leverage configurations and holds them. Fewer actions mean less operational churn, less breaker wear, and less demand on operator attention.
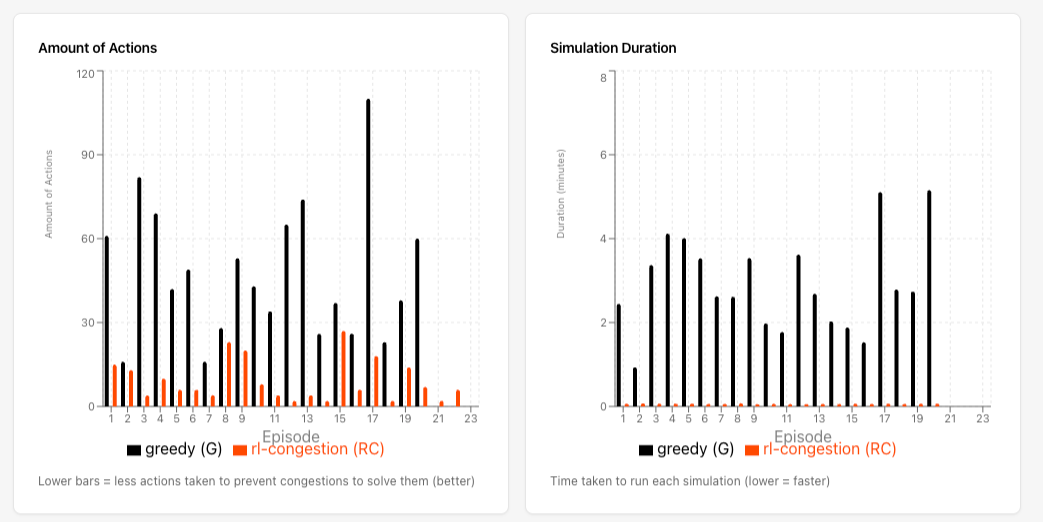
Figure 4 (left): Number of topology actions across agents. The RL agent uses fewer actions than the Greedy baseline, indicating lower switching churn. Figure 4b (right): Simulation duration across agents. The RL agent is significantly faster at runtime because inference replaces repeated action enumeration.
1. Runtime performance
The runtime result is just as important as the survival result. The Greedy policy must simulate many possible topology actions at each decision point, which makes it computationally expensive. In our benchmark runs, this can take several minutes per episode (Figure 4b).
The RL agent shifts that computation into the offline training phase. At runtime, it only performs neural-network inference, so candidate actions can be proposed in milliseconds. That is the key operational advantage: the agent does not need to solve the topology-optimization problem from scratch every time the grid state changes. It has already learned a policy in simulation and can apply it quickly when the operator needs options.
2. Interconnection compliance
The final test was whether the agent could relieve internal congestion without simply pushing the problem onto interconnection lines. This is critical for transmission grids. Cross-border capacity is not spare capacity; it supports market exchange, system balancing and reserve activation. A topology action that solves a local thermal issue but consumes reserved interconnection margin may be unacceptable operationally.
We designed the multi-objective reward function to avoid that failure mode. It combines internal thermal loading with an interconnection-capacity objective, so the agent learns to relieve congestion while keeping cross-border flows within a predefined safety threshold.
The results show that the RL agent maintains materially lower interconnection loading than the Greedy baseline. The Greedy policy reduces internal line loading, but does so partly by shifting flows onto interconnection lines. In the benchmark, the Greedy baseline pushed interconnection loading to an average of 0.65, while the RL agent kept interconnection loading below the defined threshold without significantly worsening internal loading elsewhere (Figure 5).

Figure 5. Interconnection line loading across agents. The RL agent respects the interconnection constraint more consistently than the Greedy baseline.
3. What this demonstrates
These results show that AI-enabled topology optimization is technically promising as a decision-support layer. In benchmark simulation, the RL agent survived more episodes, reduced congestion events, required fewer topology actions, and better respected interconnection constraints than a Greedy baseline.
What it does show is that topology optimization can become more operationally usable. A trained agent can quickly search a large action space, balance multiple objectives, and surface candidate actions in a form that an operator can validate. Reaching a production-ready system requires further development tuned to a specific grid: its topology, operating procedures, congestion patterns, and interconnection constraints. But the method works, and the potential is real.
Exploring the potential in your grid
Topology optimization is not a generic plug-in. Its value depends on the details of a specific network: topology, operating procedures, congestion patterns, interconnection constraints, and the way operators build trust in recommendations.
That makes exploration the right starting point. For some teams, the right starting point is a technical walkthrough of the agent, the simulation environment, and the human-in-the-loop interface. For others, the most useful first step may be a historical shadow analysis: replaying past congestion events and asking what recommendations the agent would have surfaced at each moment, without touching live operations.
From there, a controlled pilot on a network model can show how the approach performs under your own constraints and baselines. The important question is not whether an AI model can optimize a benchmark. It is about whether it can help your operators see safer options faster in situations where decisions are hardest.
That is the conversation we would like to have.
This article focused on one concrete lever: AI-supported topology optimization. More broadly, ML6 helps energy and utilities organizations turn AI into practical decision support across planning, CAPEX delivery, operations, customer flexibility, and knowledge retention. Explore our Energy and Utilities work.
References
- Rijksoverheid, IBO Bekostiging Elektriciteitsinfrastructuur, Schakelen naar de toekomst, 2025. Key figures used: more than 20,000 pending connection requests, EUR 195bn cumulative investment challenge to 2040, EUR 107bn onshore grid, EUR 3.5bn-EUR 22.5bn potential onshore CAPEX reduction through better utilization measures.
- TenneT, Annual Market Update 2025. Used for congestion-management and redispatch trend context.
- DNV. Onderzoek Zwaarder Belasten Technische Oplossingen. Ministerie van Economische Zaken en Klimaat, April 2026.
- InnoSys 2030 – Innovations in System Operation up to 2030: Factsheet – Mechanism of Curative Remedial Actions.
- Grid-enhancing technologies for clean energy systems (Nature Reviews Clean Technology)
- Elia Group. OptiOmni Project, Moonshot Program and Open Innovation Challenges. 2025.
- Wang, Yaxin, Donglian Qi, and Jianliang Zhang. "Multi-Objective Optimization for Voltage and Frequency Control of Smart Grids Based on Controllable Loads." Global Energy Interconnection, vol. 4, no. 2, 2021, pp. 136-144.
- Schulman, John, et al. "Proximal policy optimization algorithms." arXiv preprint arXiv:1707.06347 (2017).
- Donnot, Benjamin, et al. "Introducing Machine Learning for Power System Operation Support." Proceedings of the IREP Symposium, 2017.
- Donnot, “LightSim2Grid: a lightweight simulator for power systems with Python,” Grid2Op / RTE France, open-source software documentation. Available via the official LightSim2Grid documentation and GitHub repository.


