
Introduction
When designing real-world NLP applications, you are often confronted with limited (labeled) data, latency requirements, cost restrictions, etc. that hinder unlocking the full potential of your solution.
A hybrid setup where you leverage domain knowledge to improve accuracy, efficiency, reliability and/or interpretability would be perfect.
But figuring out how to design such a hybrid solution is far from evident.
Let’s browse through some common hybrid NLP design patterns and look at example situations of when you should opt for which pattern.
(1) Rules VS ML
 Pure ML-based design pattern
Pure ML-based design pattern
 Pure rule-based design pattern
Pure rule-based design pattern
The first pattern we’ll consider is the adversarial case: you either choose a pure rule-based or a pure ML-based solution.
Let’s consider some examples where these design patterns make a lot of sense
Named Entity Recognition (NER): the choice for or against an ML-based approach essentially boils down to how contextual the entities are.
For example, dates can be structured in a specific way (e.g, “DD/MM/YYYY”). If an entity follows this format, it is a date and otherwise it isn’t. Thus, it is a very “non-contextual entity”: i.e., a concrete fixed pattern determines whether or not it is a date, independent of the context.
It is straightforward to extract these kinds of entities purely via simple rules.
 A simple RegEx rule can easily recognize both dates
A simple RegEx rule can easily recognize both dates
However, say you only want to extract dates of birth and not other kinds of dates. Now, we are dealing with a very “contextual entity”: dates of birth and other kinds of dates look exactly the same; without any context, you wouldn’t be able to distinguish between the two.
It is very difficult to extract these entities in a rule-based way so a pure ML-based approach is the most appropriate.
 A contextual language model predicts that only the first date is a date of birth
A contextual language model predicts that only the first date is a date of birth
Text classification: in text classification use cases, the underlying features that determine which class a text belongs to are often very latent. As rule-based systems don’t tend to perform well in these scenarios, a pure ML-based design pattern is usually the way to go. The same goes for complex tasks such as keyword extraction, text summarization, etc.
 Some tasks are just too complex for rule-based approaches to have a meaningful impact
Some tasks are just too complex for rule-based approaches to have a meaningful impact
(2) Rules after/before ML
 Rule-based pre-processing design pattern
Rule-based pre-processing design pattern
 Rule-based post-processing design pattern
Rule-based post-processing design pattern
The next pattern we’ll look into has a sequential nature: the business rules either act as a first filter or as a post-processing step for the ML model.
Let’s take another look at some examples:
High-pass filter: say you want to extract dates of birth and no other dates, so you might opt for a pure ML approach (see above). However, only a fraction of your data actually contains dates, so running inference on every single instance seems like a bit of a waste.
We know that every date of birth is also a date and that dates follow a fixed pattern. Thus, we can first check whether a text contains a date via a simple business rule and then only run inference in the cases that it does.
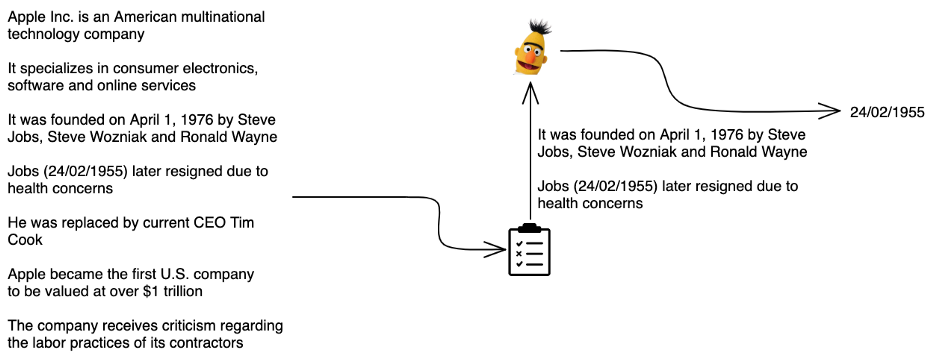 With one simple rule, we only do inference on 2 passages instead of 7 with no impact on performance
With one simple rule, we only do inference on 2 passages instead of 7 with no impact on performance
With a few simple rules, you can often drastically reduce the amount of processing power you use with a minimal to non-existent impact on performance.
(Semantic) search: in a very similar fashion to what’s outlined above, you can reduce the amount of data you process to perform a semantic search by first filtering out those results for which you are (almost) certain that they are not going to be relevant (e.g., have a (near) zero TF-IDF score). This kind of setup is referred to as a “retrieve and re-rank” architecture.
Depending on the data, a double-digit percentage decrease in latency is often attainable with a negligible impact on search performance.
Entity linking: let’s say we want to extract product names along with sales prices and link the two entities together (i.e., figure out which sales price belongs to which product name). We know our data and we make the simple assumption that a sales price belongs to the closest product name.
This is a rule-based post-processing (“linking”) step that happens after the ML-based extraction of sales prices and product names.
 A simple rule will link the ML-extracted entities together
A simple rule will link the ML-extracted entities together
(3) Rules & ML
 Ensemble design pattern
Ensemble design pattern
This pattern looks to combine the outputs of rules and ML as an ensemble.
Again, let’s see some examples:
More determinism: not all mistakes are equal. Perhaps there are some patterns that you know to be correct and want your solution to get correct every single time.z
In this scenario, you can have a restrictive rule-based system that ensures that these critical situations are covered and in parallel a more generalizable ML-based system that aims to capture the other (complex) cases.
For example, you can have a curated gazetteer of names that you know to be clean and correct. These names will always be recognized. The (uncommon) names that fall outside this list will be captured by the ML model.
 A gazetteer can capture common names and an NER model picks up the more niche ones
A gazetteer can capture common names and an NER model picks up the more niche ones
Optimization for recall/precision: since you are essentially combining multiple predictions, you can optimize for recall or precision by choice of the “voting scheme” (i.e., how you go from multiple individual predictions to one final prediction).
(4) ML-informed rules
 ML-informed rules design pattern
ML-informed rules design pattern
A more niche situation could be that your use case really requires a rule-based system — be it for regulatory reasons (e.g., GDPR’s “Right to explanation”) or for other reasons — but that these rules are very difficult to determine.
In this scenario, you could use machine learning to generate optimal (RegEx) rules.
There are actually multiple ways to achieve this — ranging from natural language-to-RegEx Seq2Seq models like SemRegex to models that are trained on labeled data like the evolutionary RegexGenerator algorithm and models like TransRegex that use both natural language and labeled examples.
(5) Rule-informed ML
 Rule-informed ML design pattern
Rule-informed ML design pattern
This pattern also looks to combine rules and ML but it does so by finding an appropriate representation of RegEx results and truly integrating the domain knowledge into the model architecture.
Theoretically, this is a very clean solution but in practice, we don’t see (widespread) adoption of such architectures. Or at least not yet.
If you want to get some intuition as to what this would look like, check out this paper. But at the time of writing, we wouldn’t recommend such a design pattern.
Conclusion
In conclusion, hybrid NLP has the potential to drastically improve the accuracy, efficiency, reliability and/or interpretability of your solution, especially in low labeled data settings. That is, if you do it right.
Choosing the right setup is inherently very data- and problem-specific but hopefully the examples above have given you some intuition into which approach to take.



