
Featured
Beyond The Backflip: Investing In Physical AI
Physical AI is reshaping industrial robotics. Learn when humanoid robots deliver real ROI — and when traditional automation still wins.
Physical AI is reshaping industrial robotics. Learn when humanoid robots deliver real ROI — and when traditional automation still wins.

Agentic Sales helps sales teams turn route-to-market signals into faster commercial action across FMCG, Retail, Lifestyle, Automotive, and Industrial.

Grid congestion will not be solved by build-out alone. See how operator-in-the-loop AI can help grid operators make better use of existing infrastructure through topology optimization.

Anthropic Fable 5 outperforms Opus 4.8 on complex coding and security tasks. Learn when the upgrade is worth the cost—and when it isn’t.

Discover why containment, not deflection, is the key metric for Voice AI in customer service, enhancing resolution and satisfaction for both customers and agents.

Discover why frictionless design fails in AI, emphasizing the need for thoughtful interfaces that enhance user decision-making and engagement.

Discover why "vibe coding" fails in enterprises and how to successfully integrate AI into software delivery through a comprehensive operating model shift.
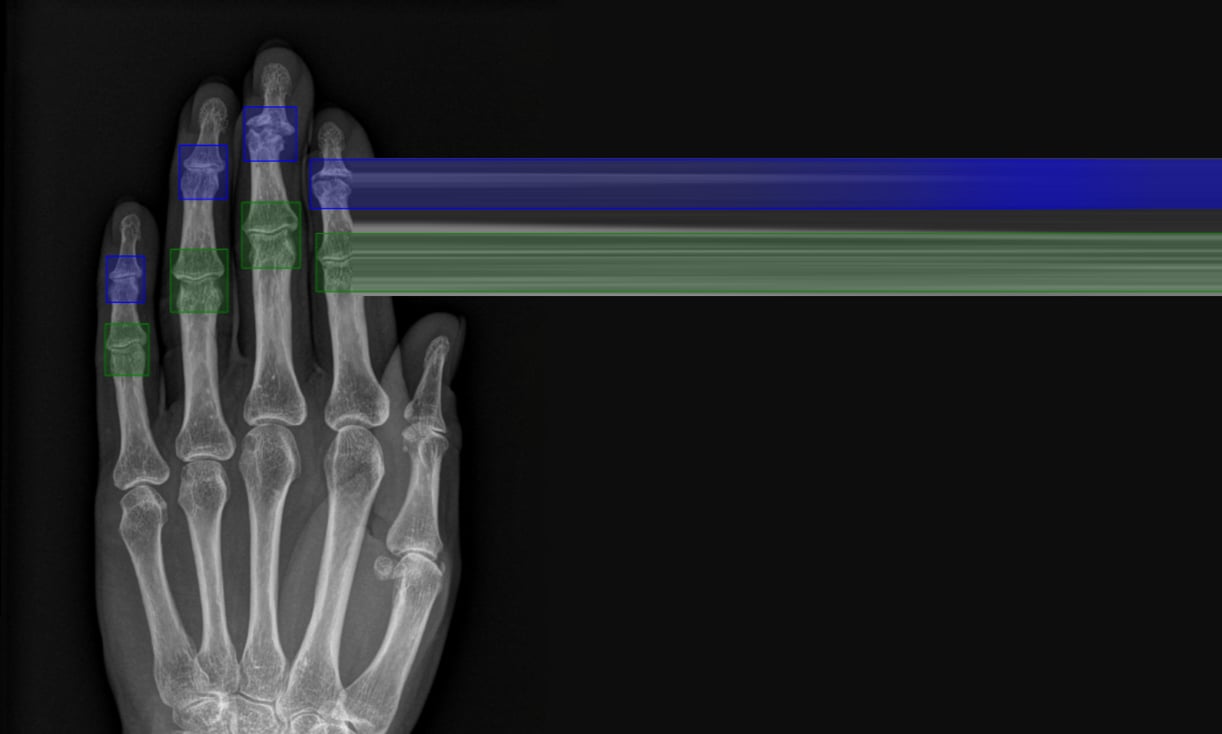
Explore how a team developed an AI pipeline to score erosive hand osteoarthritis from X-rays, achieving significant clinical improvements in just one week.

What is the environmental impact of generative AI? Explore energy use, carbon footprint, and why AI’s impact is so difficult to measure.

A practical guide to migrating Lovable apps to the cloud, covering service layer design, 3-tier architecture, and incremental migration without rewriting.