Navigating Ethical Considerations: Developing and Deploying Large Language Models (LLMs) Responsibly
.png)
Large language models (LLMs) are taking the world by storm. An avalanche of use cases is being unlocked each day, and there are no signs of slowing. Various industries -also those previously thought to be “safe” from automation, see their core business change at neck-breaking speed.
As machine learning engineers, we find ourselves at the forefront of developing and deploying these models that have the potential to transform numerous industries. While these advancements offer exciting possibilities, it is essential to address the ethical considerations and implications that arise from their development and deployment.
In this blog post, we aim to shed light on key ethical considerations and provide practical guidance to our fellow developers and clients, ensuring responsible LLM development.
The Power of Language Models
Large language models, such as GPT-4 by OpenAI, represent a significant leap in artificial intelligence technology, demonstrating a powerful ability to generate and understand human-like text. These models can author compelling prose, answer questions, translate languages, tutor in diverse subject matter, and even write computer code. As we delve deeper into the age of AI, the power these models hold is profound. They can democratize information by providing access to knowledge and learning tools to anyone with internet access and have the potential to revolutionize industries, from healthcare to education. However, this power is not without its complexities. While such models can drive incredible innovation and societal benefits, they also raise critical ethical considerations that must be addressed to ensure that their deployment does not lead to unintended negative consequences. With the rise of LLMs and foundation models (FMs), we need to move more and more toward putting energy into model alignment and keeping them under control.
In this blog post we will focus on three key aspects under which most ethical considerations can be categorized:

Toxicity
Some LLMs are supposedly trained on “the entire internet”. While this breadth of data can enhance the model’s capabilities and is the reason why it’s so good at understanding and producing human language, it also includes data that we rather have not reflected in the output of our model. This includes but is not limited to language or content that is harmful or discriminatory, particularly towards marginalized or protected groups.
To counteract this, carefully curating your training (and fine-tuning) data while ensuring a diverse and representative dataset is crucial. We must ensure that the dataset is both diverse and representative, yet devoid of harmful content. This is not just about removing offensive content, but about promoting inclusivity and fairness in the AI’s responses.
Guardrail models
One step further is to train a ‘guardrail’ model which detects and filters out any inappropriate content in the training data or the data produced. This model is trained on examples of both appropriate and inappropriate samples. The goal is for the model to learn to distinguish between acceptable and unacceptable content. Once trained, this model is used for filtering the training or fine-tuning data, or it’s integrated with the primary LLM. Every time the primary LLM generates output, it’s also passed through the guardrail model. The guardrail model then flags the output for review, blocks it, or guides the primary model to modify it.

Reinforcement Learning with Human Feedback (RLHF)
Humans can also be involved to label data in order to avoid toxic or harmful content and encourage the useful completion of a task. This is done by letting human annotators rate multiple completions of your LLM for one prompt at a time. This data is then used to train a reward model which takes over the human’s task of rating and forwards the scores to a Reinforcement Learning model to update the weights of the LLM.
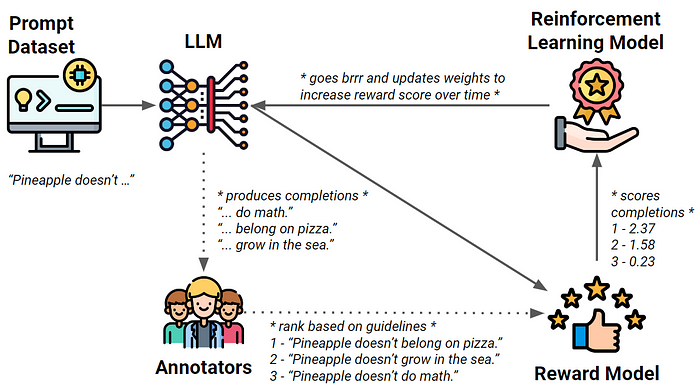
When the data first needs to be annotated for training the LLM or a reward model, make sure to provide your annotators with enough guidance on how to label certain data. Additionally, selecting a diverse group of annotators helps avoid potential biases and contributes to a more balanced and representative model.
Careful prompt design
Lastly, being careful in your prompt design can help mitigate toxicity. Instead of:
“Explain why people who like pineapple on pizza have bad taste.”
which assumes a negative stereotype and could perpetuate divisive attitudes, you could ask:
“Discuss the varying global perspectives on the topic of pineapple as a pizza topping, making sure to represent all views in a respectful and unbiased manner.”
setting clear boundaries for a respectful conversation.
We previously built demos to detect toxicity, profanity, and hate speech in short text for German and Dutch.
Hallucinations
What in entirely different circumstances could be a result of toxicity, is meant as the production of misinformation or ‘fake news’ in the context of LLMs.
One explanation is that a lot of times we don’t know what model is actually learning when presented with a certain dataset. Consequently, the model will attempt to fill gaps where it’s missing data.
Using LLM parameters
Many models allow for parameters to be adjusted. The most common ones which influence the model’s “creative freedom” (and thus indirectly its hallucination) are temperature, top_p, and top_k. The more factual your use case, the stricter you should be with these parameters:
- temperature set to 0 makes the model deterministic. The higher the temperature value, the more diverse and random the output.
- top_p limits the model’s output to the combined top p% of the probability distribution.
- top_k limits the model’s output to the top k most probable tokens of the probability distribution.
With all these parameters set to low numbers, an LLM could produce something like
“The cat sits on the balcony, meowing at the pigeons.”
Experimenting with these parameters, the same prompt could result in something like this:
“The cat sits on the moon, meowing at the stars.”
So choose your parameters wisely.
Source verification and RAG
Another way to limit hallucination is augmenting the LLM with independent and verified sources to cross-verify the data returned by the model. This can be triggered by prompting the LLM to state its source each time it claims to produce a response with facts (e.g. “refer to the source of the information you provide in your response” or “only answer if you can refer to the source of the information you provide. If you can’t answer the question, say < … >”). This can help users ascertain the reliability of the information.
Taking this one step further would be using retrieval-augmented generation (RAG) which adds a knowledge base to your LLM. We refer to another blog post explaining its concept and implementation.
You can combine source verification and RAG to achieve even better results.
Careful prompt design
This can be another effective way to avoid hallucinations and steer the LLM toward more useful responses. Therefore give clear context and create prompt designs which are as specific as possible and avoid ambiguity. Instead of:
“Describe the famous international law passed in 2020 banning pineapple on pizza.”
which makes this prompt a source of potential misinformation, you could ask:
“Could you provide an overview of the origins and popular opinion about the ‘Hawaiian pizza’, which includes pineapple as a topping, based on information available up to 2021?”
which asks for factual information within a specific time frame, reducing the chance of the model generating fictitious or speculative information. Additionally, you can design your prompts in a way that describes the role of the LLM (e.g. “You are a customer service agent…”)
Transparency toward end users
Another simple, but important step in terms of explainability, is transparency with end users. Let the users know that they’re dealing with an artificial intelligence system and that the reality of this technology is that it can produce wrong answers. If an LLM is used for an unintended use case, its chance to hallucinate is higher. Adding disclaimers not only improves user understanding but also sets realistic expectations about the reliability of the AI system.
Legal aspects
When training or fine-tuning your LLM, you need to make sure not to run into any copyright or protection issues surrounding your data and model.
Data Protection
From a legal perspective, you need to be aware of where your model and your data are hosted in order to comply with data and privacy protection regulations. This for example includes not storing or using personal data without a legal basis and respecting inter alia the general principles of (i) data minimization, (ii) purpose limitation, (iii) storage limitation, (iv) accuracy, (v) fairness and transparency and (vi) integrity and confidentiality.
Intellectual Property
The question of intellectual property is currently widely discussed due to the lawsuits in the US against various companies training LLMs. LLMs learn from vast amounts of data, often ingesting copyrighted material, such as books, articles, or web content, during their training phase. Does an LLM now infringe intellectual property when copyright-protected works are used to train or finetune, or when it generates text based on a copyrighted source?
It will be very interesting to see how judges in different jurisdictions deal with this question.
At the time of this writing, we are looking for a solution to this debate, by establishing a framework that facilitates collecting and preprocessing image data for foundation models. The framework leverages Creative Common (CC) licensed images for creating free-to-use datasets for image generation with AI. We previously published another blog post about image generation without copyright infringement.
EU AI Act
The EU AI Act is planned to regulate the development and deployment of foundation models and thus LLMs. This includes (but is not limited to):
- Data: Describing data sources and summarizing copyrighted data used to train the foundation model. The data used is subject to data governance measures (suitability, bias, appropriate mitigation)
- Compute: Disclosing model size, compute power, and training time for training the model. The energy consumption for training needs to be measured and steps to lower the consumption need to be taken.
- Model: Capabilities and limitations of the model need to be described, as well as foreseeable risks and associated mitigations. Any non-mitigated risks have to be justified. The model needs to be benchmarked on public/industry-standard benchmarks and results of internal and external testing need to be reported.
- Deployment: Disclosing content that is generated by a model. The EU member states where the foundation model is on the market need to be stated. Technical compliance for downstream compliance with the EU AI Act has to be provided.
Conclusion
Even after following up on all these steps and building the most responsible AI system possible, the process isn’t done (and will never truly be). Creating AI systems is a continuous iterative cycle where we want to implement responsibility in the concept and deployment stages. Monitoring and updating the models is important to address emerging toxic patterns, trends, or novel misuse. This needs to be rounded up with governance policies and accountability measures for all involved stakeholders throughout the life cycle.
Building an AI system responsibly is a multifaceted task that demands a proactive approach, careful planning, and ongoing commitment. But the payoff — a reliable, user-friendly system that respects and safeguards users’ interests and societal values — is worth the effort.
The development and deployment of AI systems represent a significant technological advancement. However, along with this progress comes the responsibility to ensure that the use of such technology is ethically sound and respects the rights and values of all stakeholders. By understanding and addressing the ethical considerations involved, we can harness the full potential of AI while minimizing the risks and harm associated with it.
Thank you for bearing with me until the end! I hope you found this blog post useful. In case you’d like to read more about LLMs from my wonderful colleagues, this way please:
Other resources:
- State of the LLM
- Low-Rank Adaptation: A Technical Deep Dive
- Google’s new Generative AI offering
- ChatGPT & GPT-4: Gimmicks or game-changers?